← Back to Blog
Kato TechStack Standards — Data Architecture, Engineering & AI
“In the era of AI, the new architecture isn’t just about pipelines — it’s about creating systems that learn.”
As a Data Architect and Senior Data Engineer, I focus on designing scalable data ecosystems where AI and analytics can thrive together. This document defines my Tech Stack Standards — a blueprint for building data-driven platforms that support both analytical workloads and machine learning systems from day one.
🧱 Core Architecture Philosophy
-
Data-Centric Foundation Build once, use everywhere — data should be usable across analytics, ML, and real-time decisioning.
-
Schema as Contract Every dataset has a defined lifecycle — from ERD to metadata catalog to production schema registry.
-
Observability + Explainability Design for traceable data flow and model lineage — critical for AI governance and debugging.
-
Composable Systems Choose modular tools across ingestion, processing, storage, and inference. Interoperability > monolith.
☁️ Cloud & Infrastructure
Core Stack
- Compute & Storage: AWS (S3, Redshift, EMR), GCP (BigQuery, Vertex AI), Azure (Data Factory, Synapse)
- Containerization: Kubernetes, Docker
- IaC: Terraform, Jenkins, CI/CD automation
- Observability: Grafana, Prometheus, ELK stack
- Security: IAM, Apache Ranger, Cloudflare edge protection
🧮 Data Warehouse & Lakehouse Standards
Warehousing Layers
- Staging → Core → Mart modeled using dbt
- Batch & Realtime pipelines unified via event streaming (Kafka, Flink)
- Query Engines: Trino, StarRocks, ClickHouse
Lakehouse Architecture
- Object Storage + Open Table Formats (
Iceberg,Delta,Hudi) - Unified access with Trino & Hive Metastore
- Data quality layers with Great Expectations and ydata_profiling
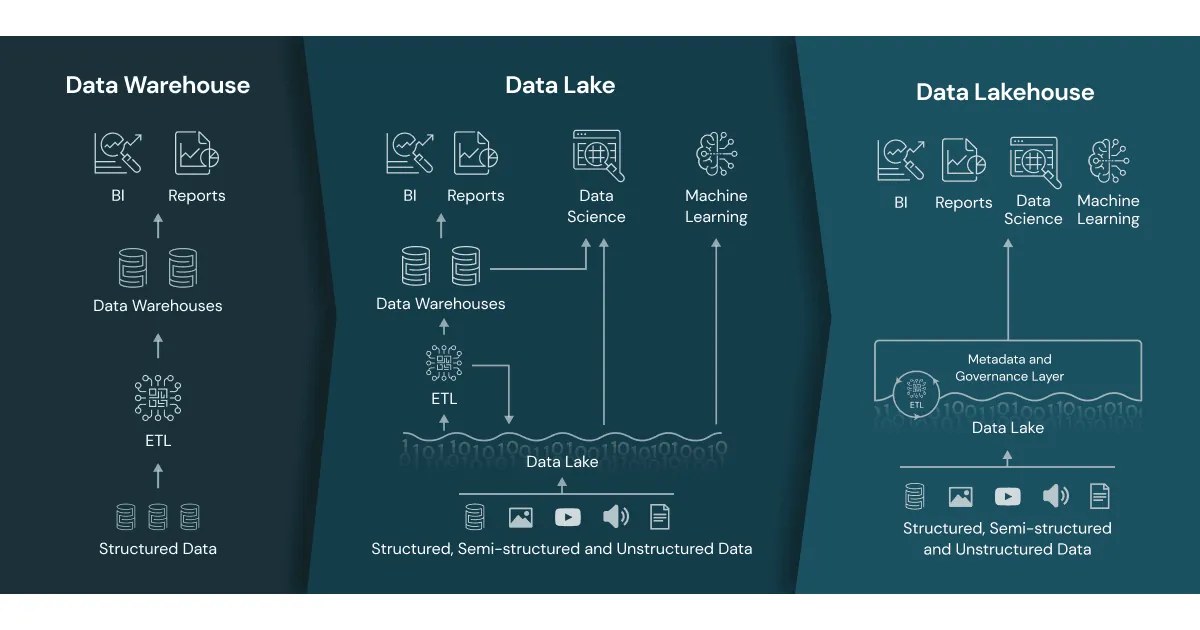 "All houses" architecture
"All houses" architecture
🤖 ML & AI Artifacts
Modern data architecture must natively support AI workflows. These components define the AI-ready foundation of my stack:
Feature Engineering Layer
- Feature Stores:
Feast,Vertex AI Feature Store, or custom Delta-based feature hubs - Reusable, version-controlled features across ML models
Model Management
- Model Registry:
MLflow,SageMaker Model Registry,Weights & Biases - Track model metrics, artifacts, and lineage
- Automated deployment triggers to inference endpoints
MLOps
- CI/CD for models with Jenkins or GitHub Actions
- Model training pipelines on Databricks, Vertex AI, or custom Airflow DAGs
- Batch and real-time inference APIs via FastAPI or gRPC services
AI Observability
- Drift detection and retraining triggers (EvidentlyAI, Arize, or custom)
- Bias testing and interpretability via SHAP, LIME, or integrated dashboards
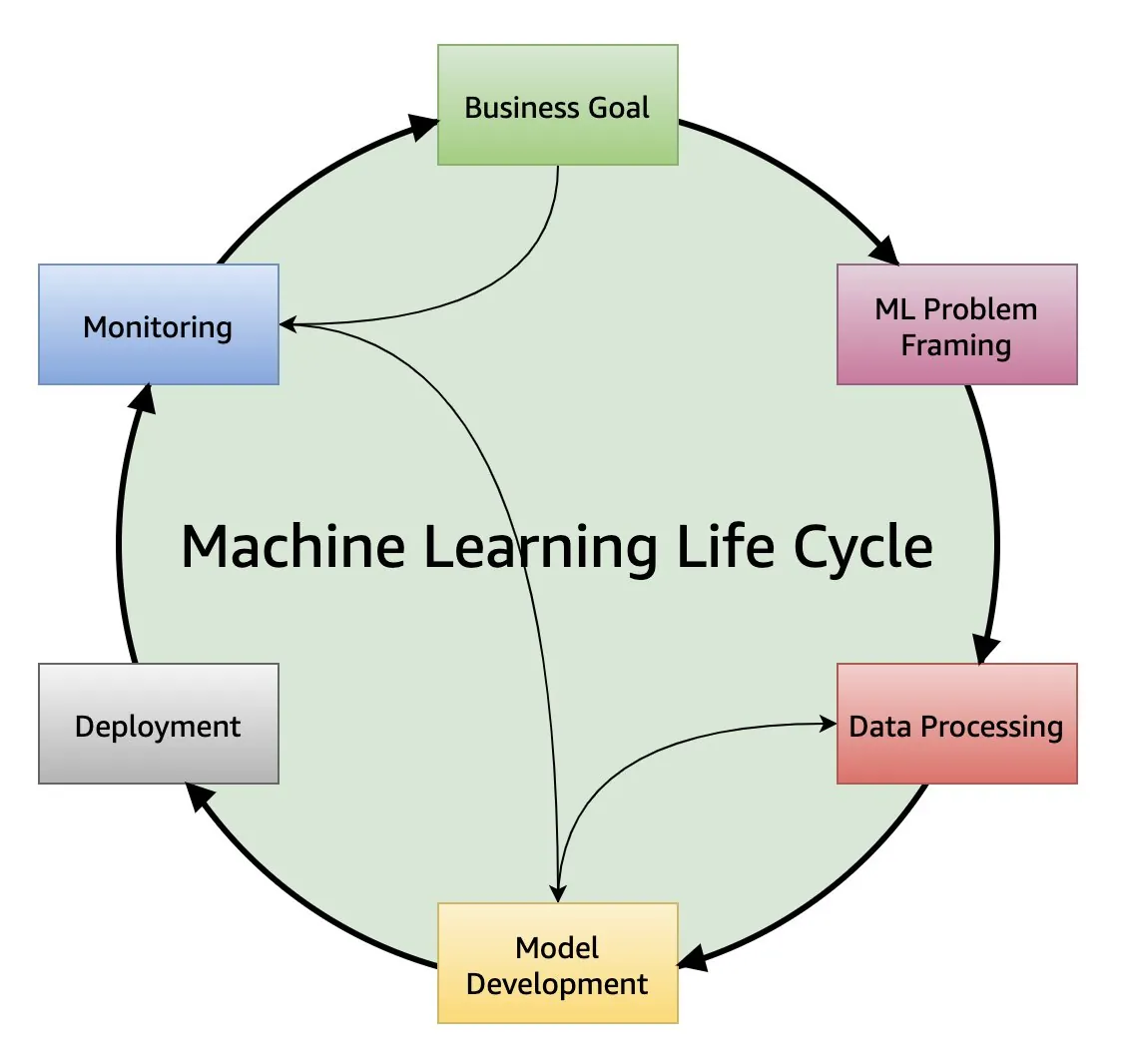 ML lifecycle
ML lifecycle
🧠 AI in SDLC (Software Development Lifecycle)
AI now acts as a co-pilot across the engineering lifecycle:
| SDLC Phase | AI Augmentation | Tooling / Example |
|---|---|---|
| Planning & Design | AI-assisted system design, architecture generation | ChatGPT, Claude, Copilot Labs |
| Development | Auto code generation, test synthesis | GitHub Copilot, Tabnine |
| Data & Model Lifecycle | Data validation, model versioning, retraining | Great Expectations, MLflow, Kubeflow |
| Testing & QA | Synthetic data, anomaly detection | Deepchecks, Faker |
| Monitoring & Maintenance | Log summarization, anomaly detection, root cause AI | Elastic AI, Datadog ML |
| Governance | Explainability, lineage, policy enforcement | OpenMetadata, AI Governance Toolkit |
 AI Overflowing Stack
AI Overflowing Stack
🔒 Data Governance, Quality & Compliance
- Governance: Apache Ranger, OpenMetadata, IAM Roles
- Lineage: dbt docs, OpenLineage
- Testing & Profiling: Great Expectations, Soda Core
- Compliance: GDPR / HIPAA / SOC2 readiness
📊 Visualization & Consumption Layer
- Enterprise BI: Power BI, Looker
- Embedded analytics: Superset, Metabase
- Realtime dashboards for operational insights
- Generative AI-enhanced insights: LLM-based BI Q&A or AI co-pilot on data
🧩 Engineering Standards
- CI/CD Pipelines: Code + Data + Model in unified workflows
- Coding Practices: Python (FastAPI, PySpark), SQL, and Java Spring Boot
- Version Control: Semantic commits + dbt model versioning
- Documentation: Auto-generated lineage and doc sync with metadata store
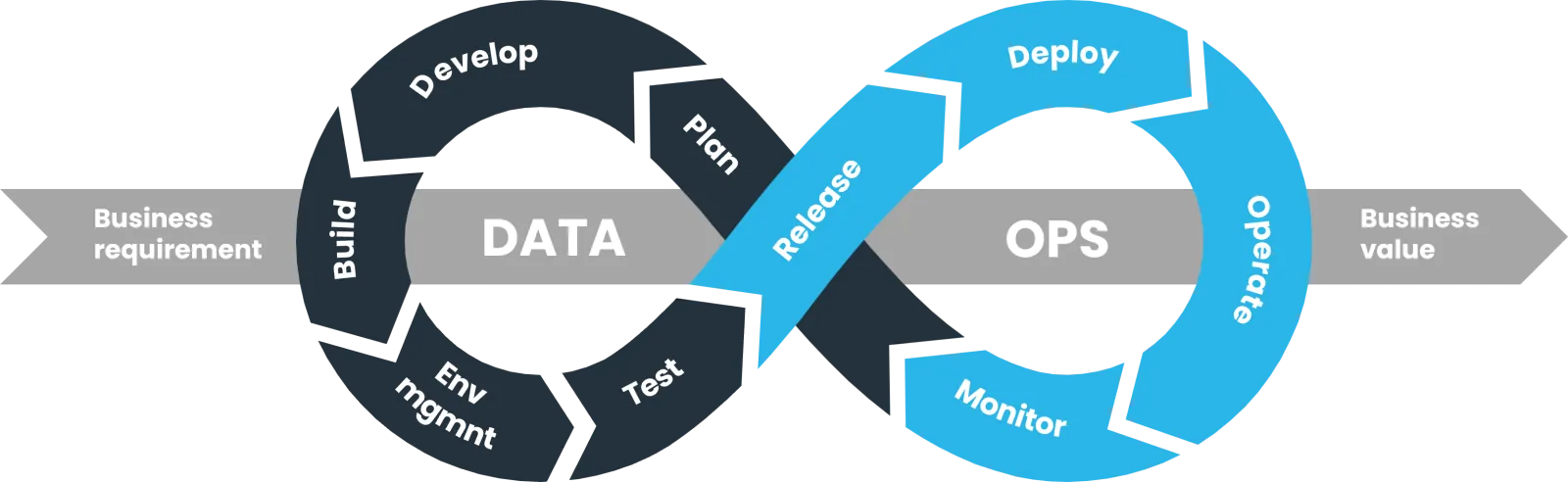 DataOps
DataOps
🏗️ Architecture Example — Healthcare AI Data Platform
Enterprise-grade healthcare lakehouse data platform architecture:
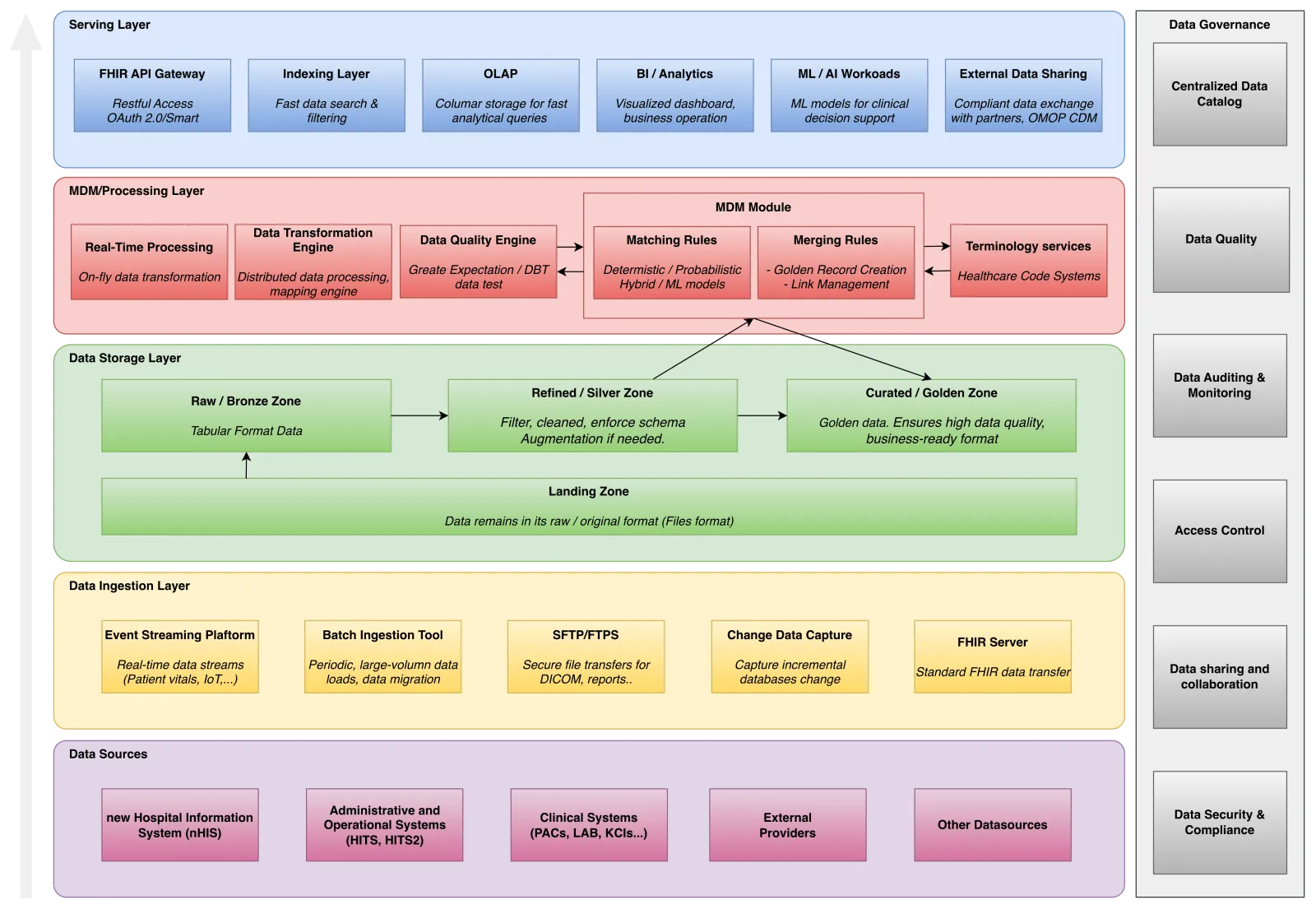 Lakehouse platform
Lakehouse platform
Design Principles:
- Vision-Aligned Architecture: Lakehouse architecture supports KPJ’s goal of a unified, scalable, and secure healthcare data platform.
- Hybrid Deployment: Built on Cloudera Data Platform (CDP) with on-prem for critical ops and cloud-ready for scale.
- Medallion Lakehouse Model: Implements Bronze, Silver, and Gold zoning for raw, refined, and curated data.
- Open Standards Compliance: Aligns with FHIR, HL7, OMOP, ICD for healthcare interoperability.
- Unified Metadata Governance: Uses Apache Atlas & Apache Ranger for lineage and metadata across all zones.
💡 Closing Thoughts
“Data Architecture is the skeleton. AI is the nervous system. Together, they form the living organism of modern software.”
The future of data platforms is AI-native — where data, models, and applications continuously learn and improve. These are my evolving standards for designing architectures that aren’t just scalable, but self-improving.
© 2025 Kato (Quan Ngo) — Architecting the data-driven future.