Azure Databricks & Spark for Data Engineers (PySpark / SQL)
Introduction
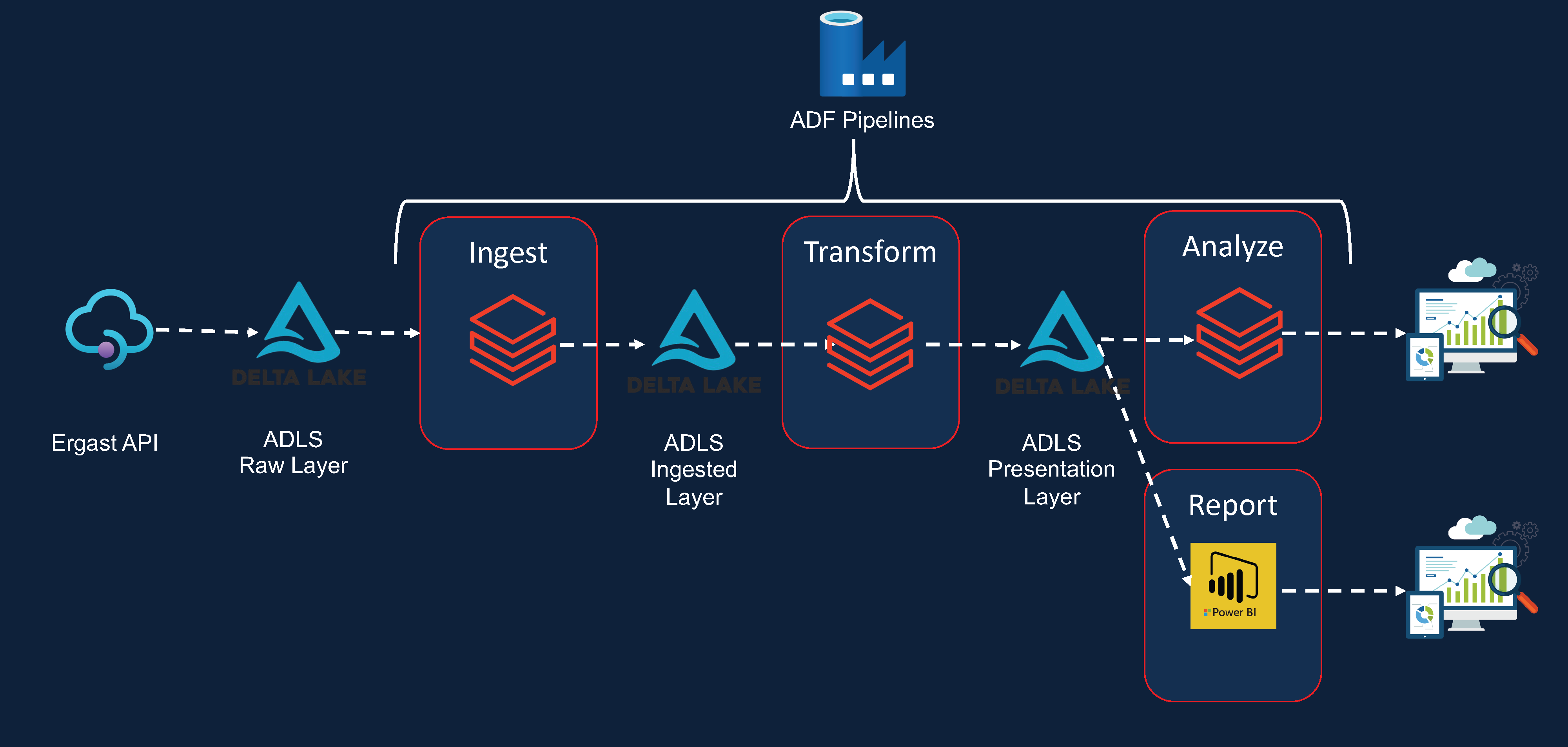
This personal project, I use PySpark on Databrick on Azure to build data warehouse with Medallion architecture
Git repo: ![]()
General concept
Hive metastore
Reference: Hive Tables
Spark SQL uses a Hive metastore to manage the metadata of persistent relational entities (e.g. databases, tables, columns, partitions) in a relational database (for fast access).
A Hive metastore warehouse (aka spark-warehouse) is the directory where Spark SQL persists tables whereas a Hive metastore (aka metastore_db) is a relational database to manage the metadata of the persistent relational entities, e.g. databases, tables, columns, partitions.
By default, Spark SQL uses the embedded deployment mode of a Hive metastore with a Apache Derby database.
Hive metastore on Databricks
Databricks manages Meta Store:
- By Databricks default
- Or by External Meta Store (Azure SQL, My SQL, PostgreSQL, MariaDB etc)
Project architecture
Techstack using on this project:
Databricks,Pyspark,Delta Lake,Azure Data Lake Storage,Azure data Factory,Azure Key Vault
Azure databricks Analytics architecture reference.
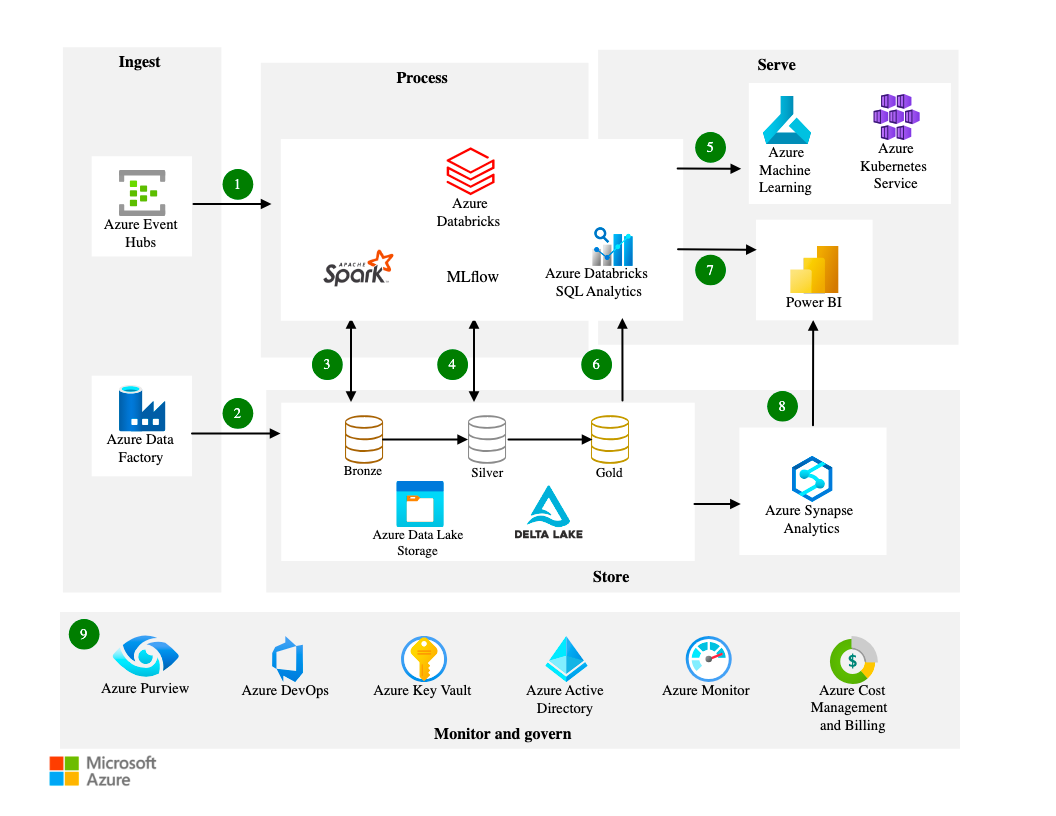
1. Set up the environments
Create Databricks Cluster
Databricks / Compute / Create compute (with below configuration):
- Policy: Unrestricted (Can create custom policy): Cluster policy definitions
For example: Set up value for spark version 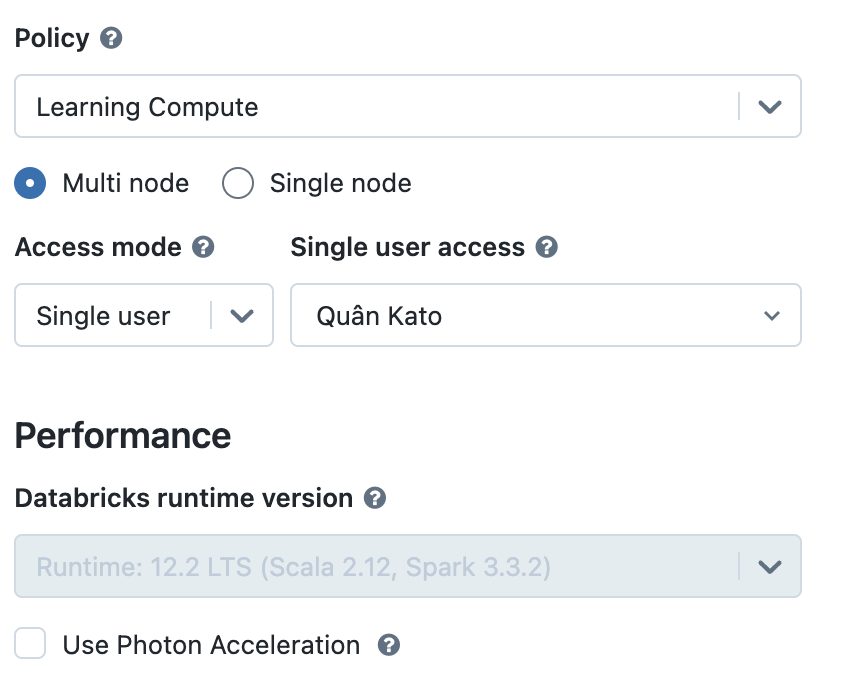 with below policy config
with below policy config
1
2
3
4
5
6
7
{
"spark_version": {
"type": "fixed",
"value": "auto:latest-lts",
"hidden": true # to hide the version
}
}
- Access mode: No isolation shared
- Node type: Standard_DS3_v2
- Termination time: 18 minutes (saving money for activity)
- Logging: dbfs:/cluster-logs/0821-080317-lq06a367
Create budgets & Cost alerts
Budget Details
- Name: az-admin-exceed-30-pounds
- Reset period: Reset period
- Amount (Threshold): 10 Alert conditions:
- Actual - 90 (%)
- Alert recipients (email): [email protected]
Create Azure Storage Account
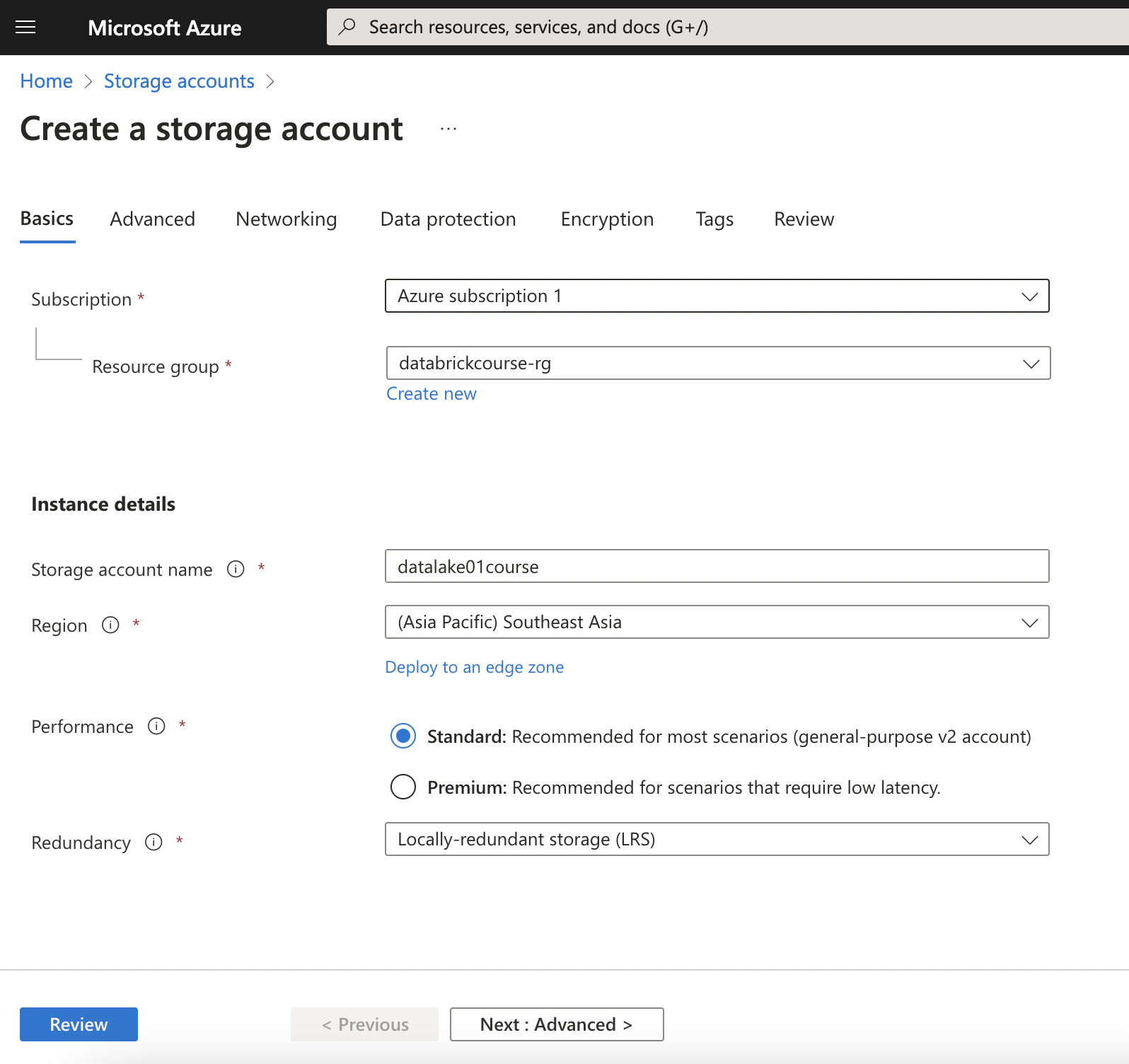
Select hierarchical to enables file and directory semantics, accelerates big data analytics workloads, and enables access control lists (ACLs)

Choose the storage account
Download storage browser
 Download
Download
Case 1: Session Scoped Authentication (Via notebook)
1. Access Azure Data Lake storage using access key
1
abfss://<container>@<storageAccountName>.dfs.core.windows.net
 The Azure Blob Filesystem driver (ABFS)
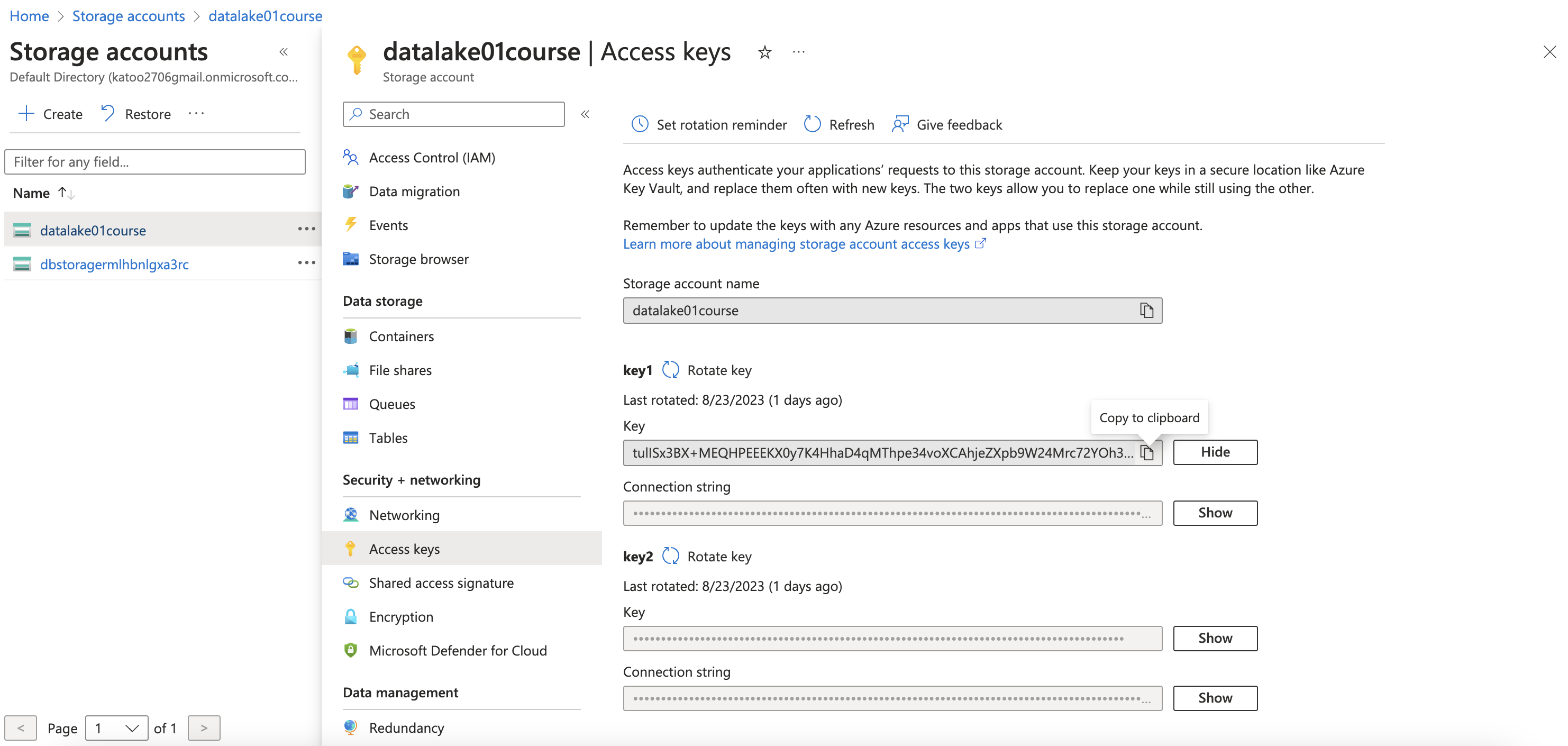
Set up the access key
https://learn.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-abfs-driver
The Azure Blob Filesystem driver (ABFS)
Set up the access key
https://learn.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-abfs-driver
1
2
3
4
spark.conf.set(
"fs.azure.account.key.datalake01course.dfs.core.windows.net",
"**access_key**"
)
2. Access Azure Data Lake storage using Shared access signature
- Connect to Azure Data Lake Storage Gen2 using SAS token
- Grant limited access to Azure Storage resources using shared access signatures (SAS)
1 2 3 4
# Set up the access key spark.conf.set("fs.azure.account.auth.type.datalake01course.dfs.core.windows.net", "SAS") spark.conf.set("fs.azure.sas.token.provider.type.datalake01course.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.sas.FixedSASTokenProvider") spark.conf.set("fs.azure.sas.fixed.token.datalake01course.dfs.core.windows.net", blob_sas_token)
Generate SAS token from container
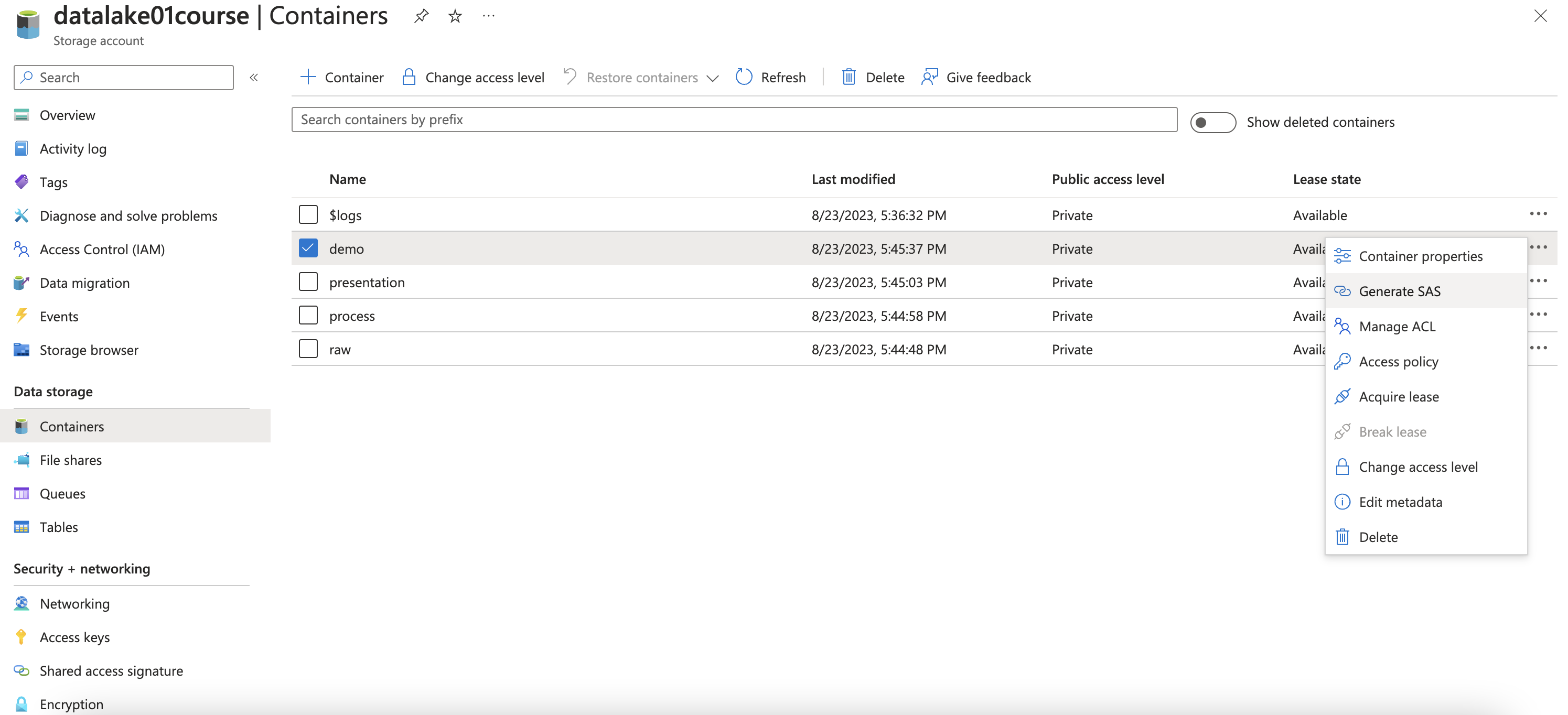
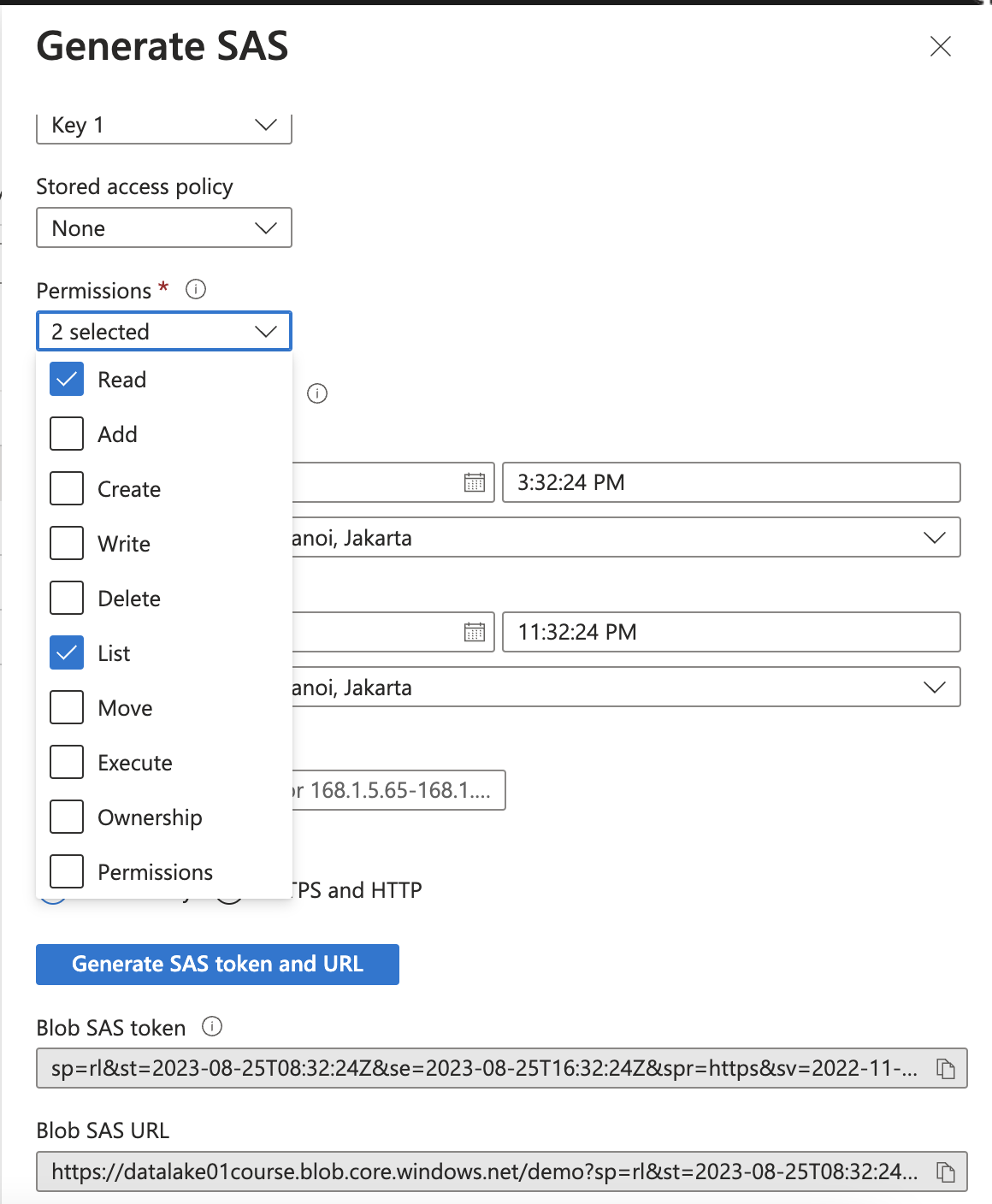
Otherwise, SAS can be generated from Microsoft Azure Storage Explorer
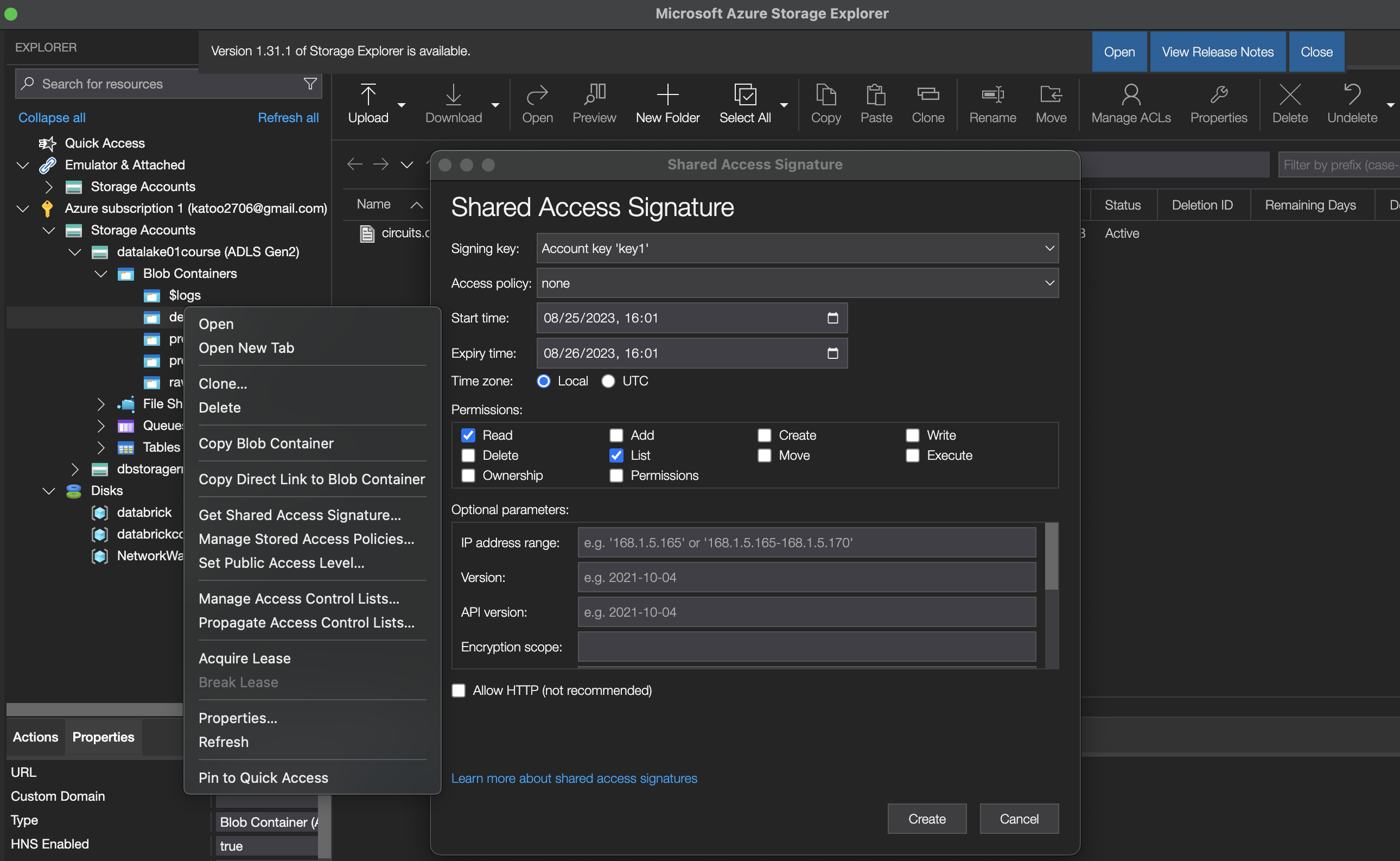
3. Access Azure Data Lake using Service Principal
Step to follow:
- Create app: Choose service Azure Active Directory / Choose App registrations / New registration (Choose default setting)
 Copy client_id, tenant_id
Copy client_id, tenant_id
1 2 3 4 5
client_id = "***" tenant_id = "***" # To get client secret, choose Certificates & secrets / + New client secret -> copy value client_secret = "***"
- Assign role to app: In storage account, choose Access Control (IAM) / Add / Add role assignment (Storage Blob Data Contributor)
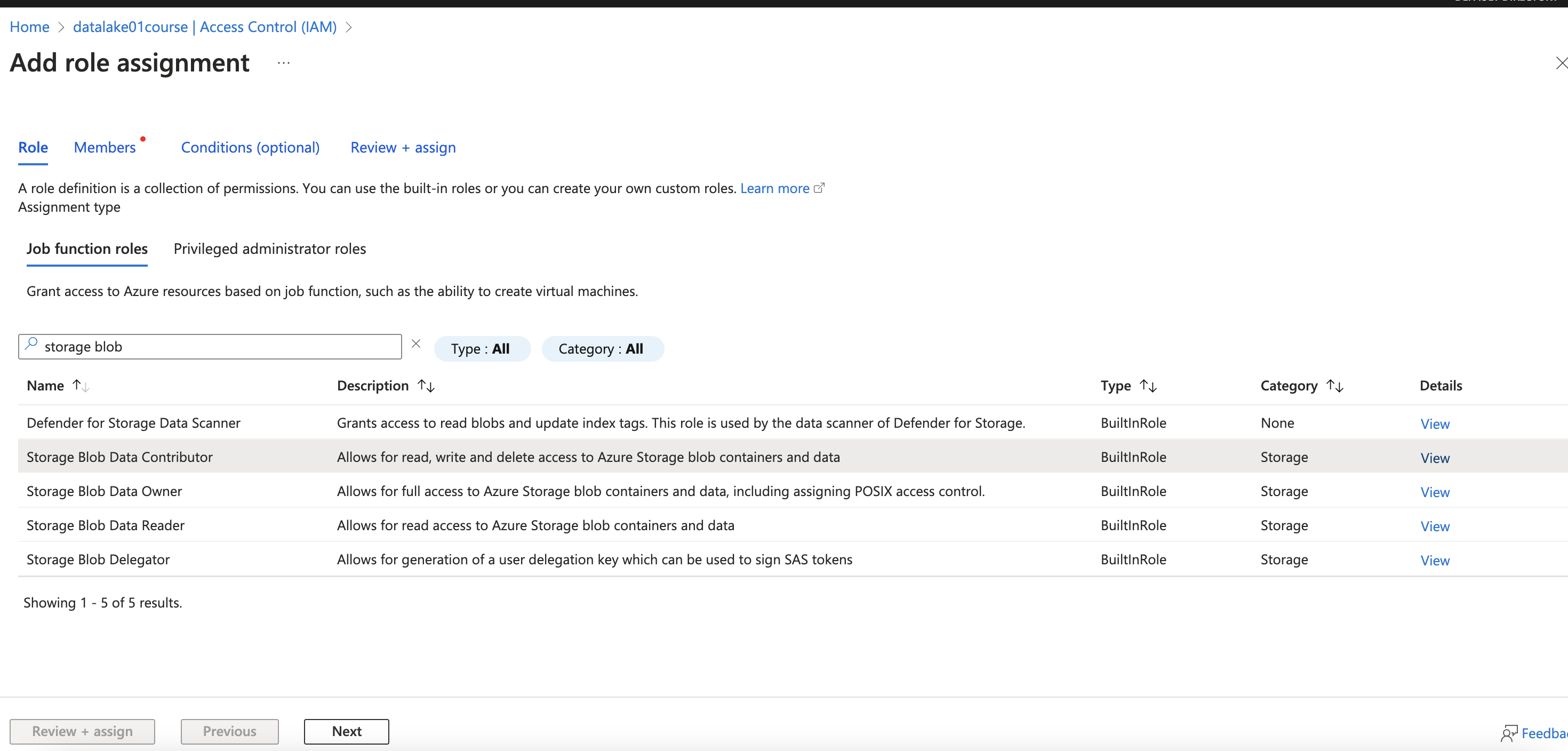
Case 2: Cluster Scoped Authentication (Via cluster)
1. Enable credential passthrough for user-level data access
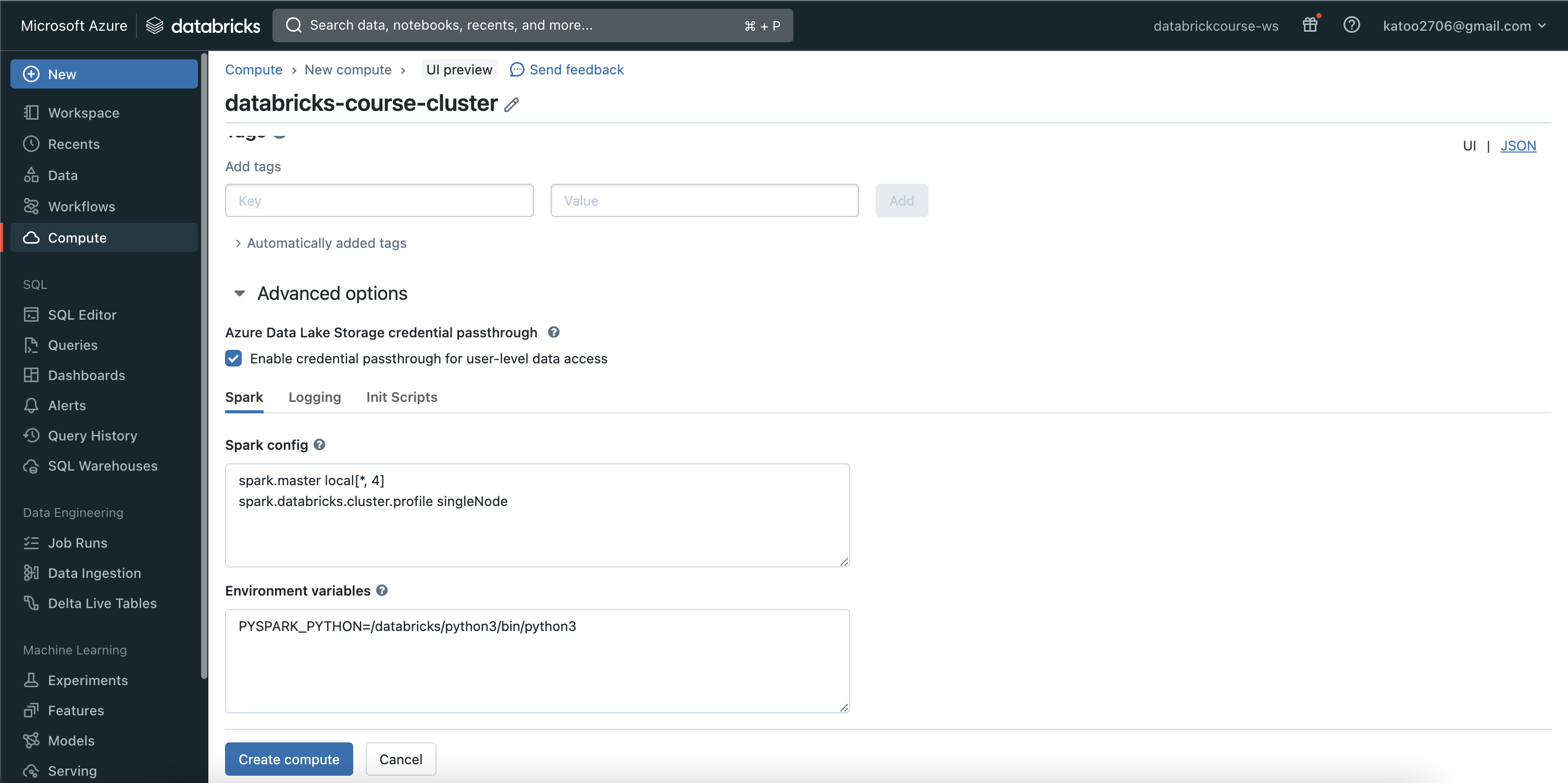
Same as Access Azure Data Lake using Service Principal, we need to grant access to creator account (who owns cluster) in Storage account
Even though I’m the owner, I do not have the role to read data from the storage account. -> Assign role to Cluster: In storage account, choose Access Control (IAM) / Add / Add role assignment (Storage Blob Data Contributor)
2. Secure Access to Azure Data Lake
Create Azure Key Vault
1
2
3
4
5
6
7
8
// Basics
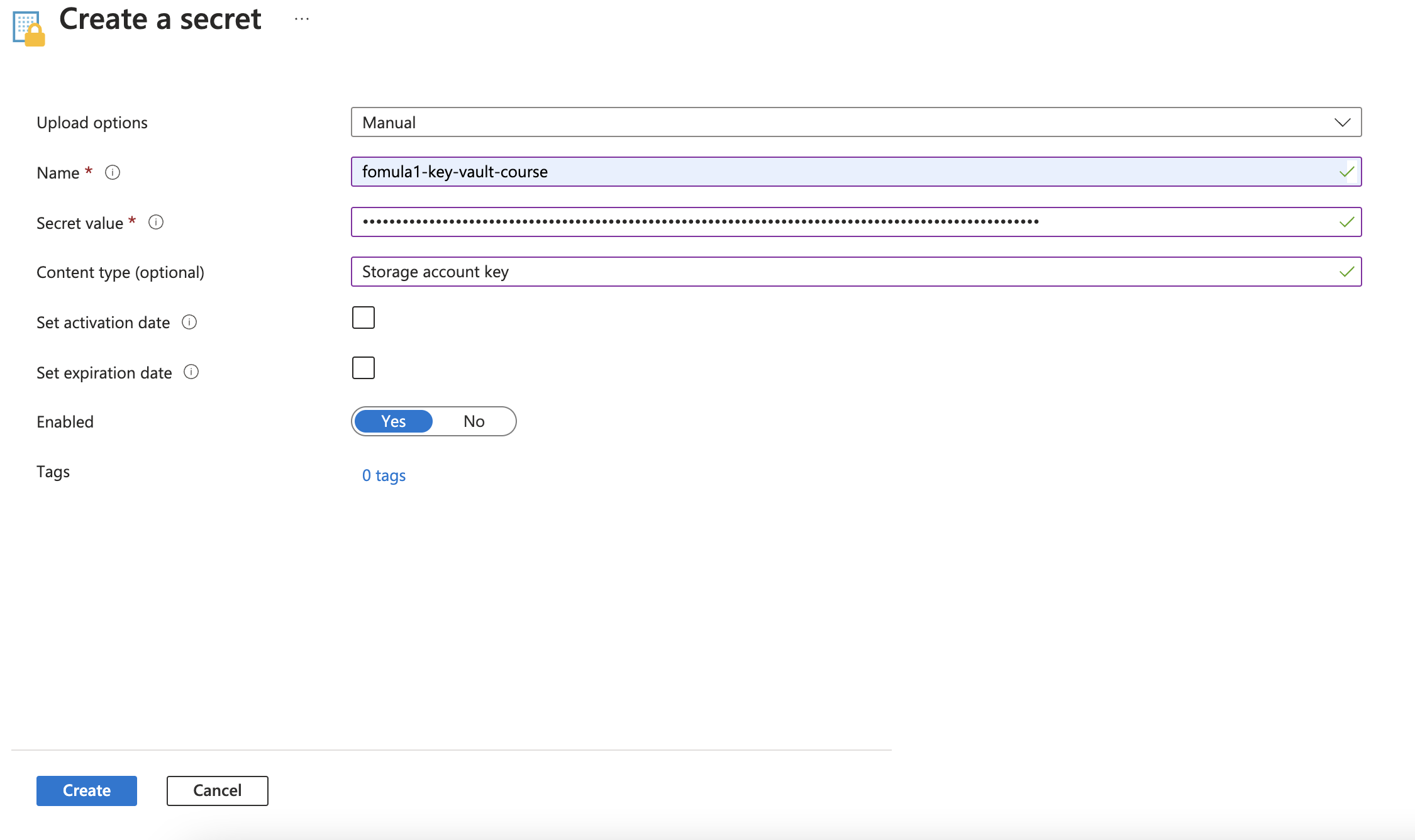
Resource group: databrickcourse-rg
Key vault name: fomula1-key-vault-course
Region: Southeast Asia
Pricing tier: Standard
// Access configuration
Permission model: Vault access policy
Create access token in Key Vault
Create secret scope in Databrick
will get scope-name
Reference: Link
Go to https://<databricks-instance>#secrets/createScope. This URL is case sensitive; scope in createScope must be uppercase.
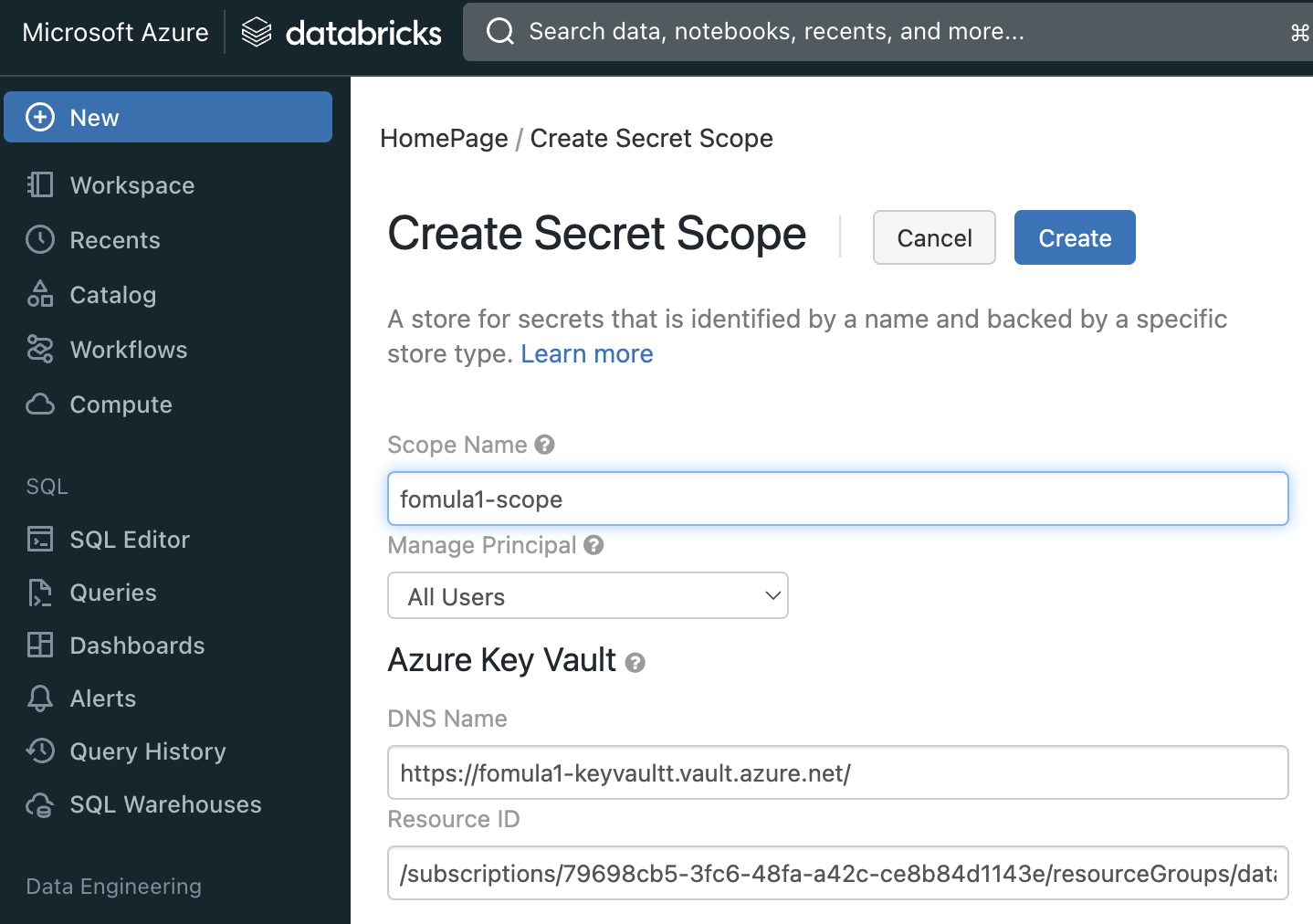
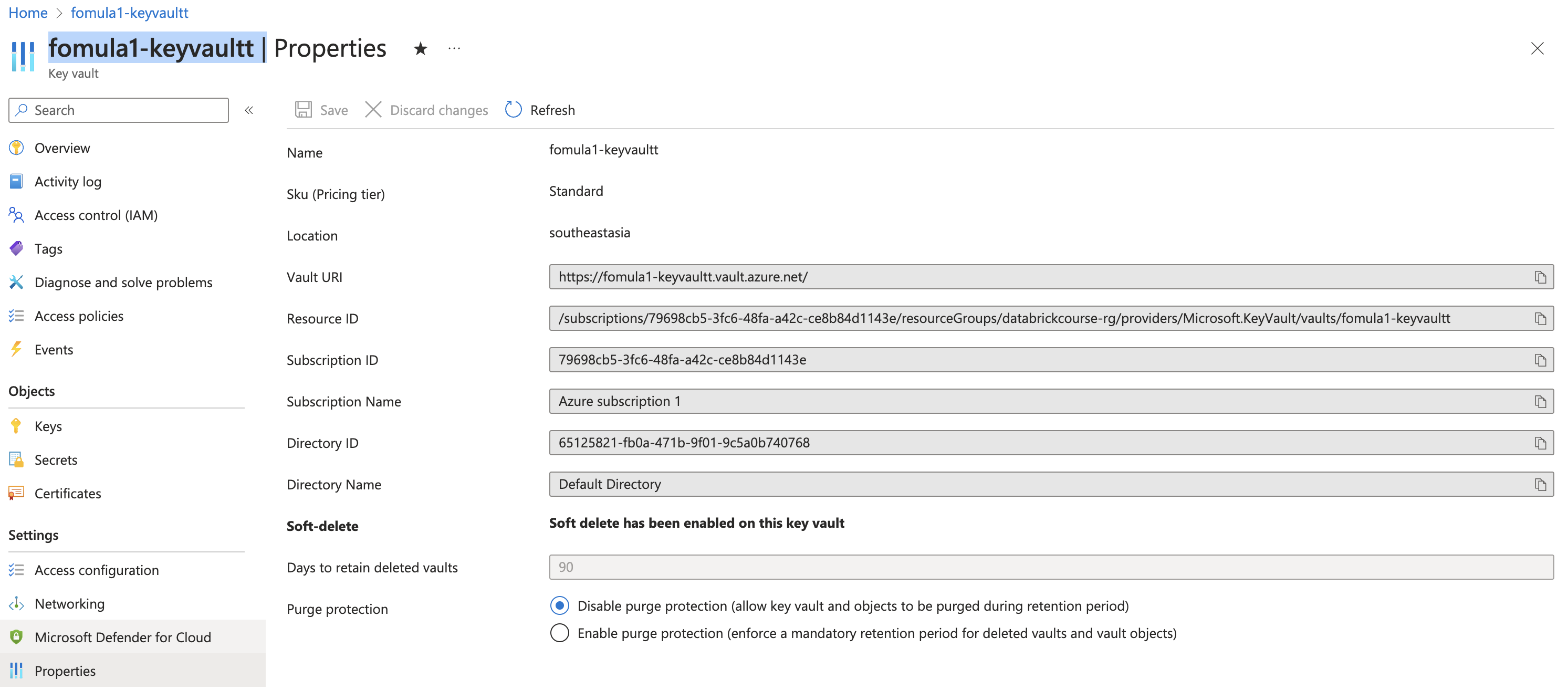
For DNS Name & Resource ID, go to key vault / Properties to get value for that
1
2
DNS Name = Vault URI
Resource ID = Resource ID
3. Mount the container onto Hive MetaStore.
4. Convert raw files into Parquet tables, Delta tables.
5. Establish either a temporary view or manage tables/external tables, utilizing SparkSQL for data visualization.
6. Azure Data Factory
Learning resource:
- Tutorial: Visit here
- Video: Visit here
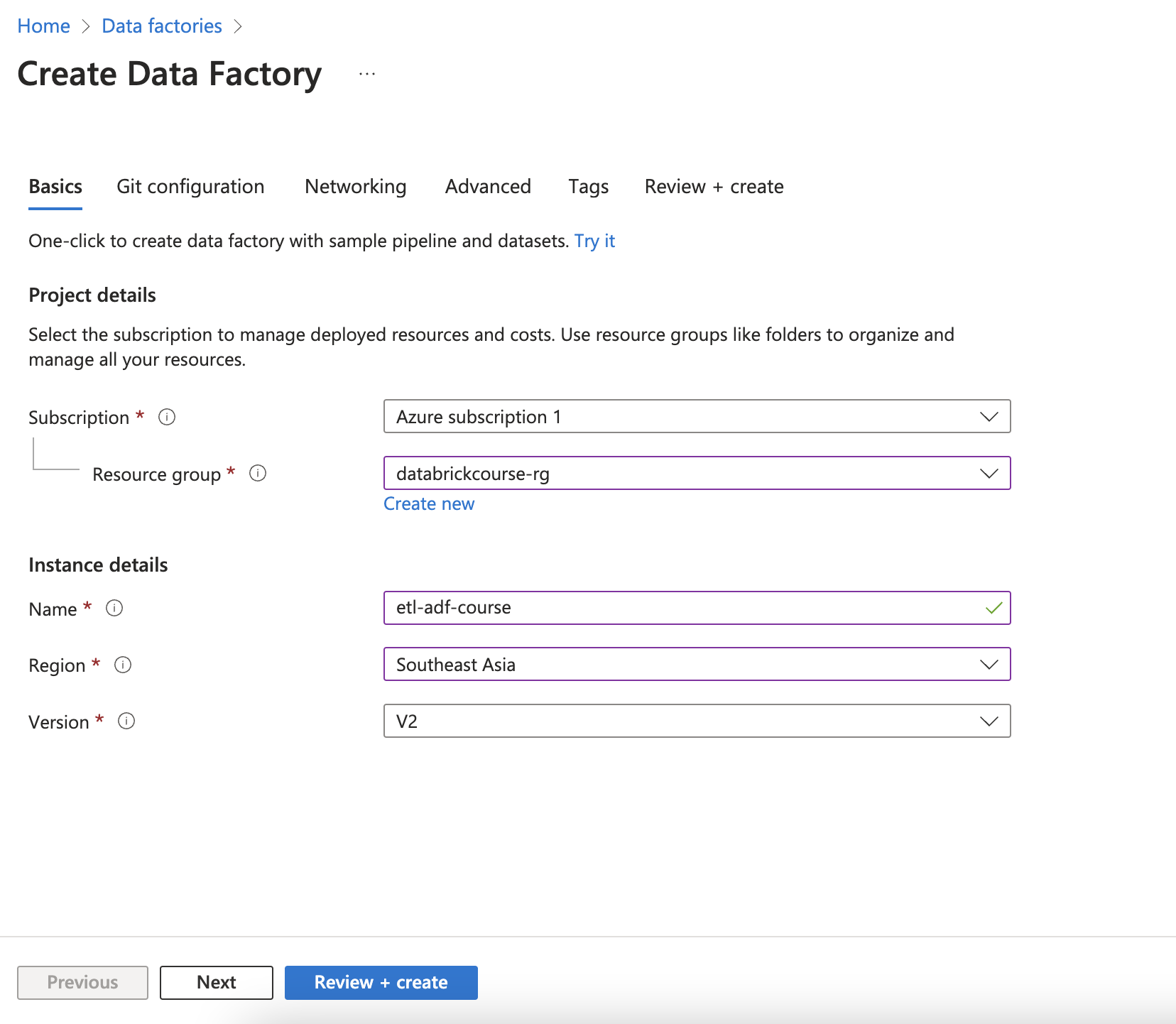
Create CI/CD with git
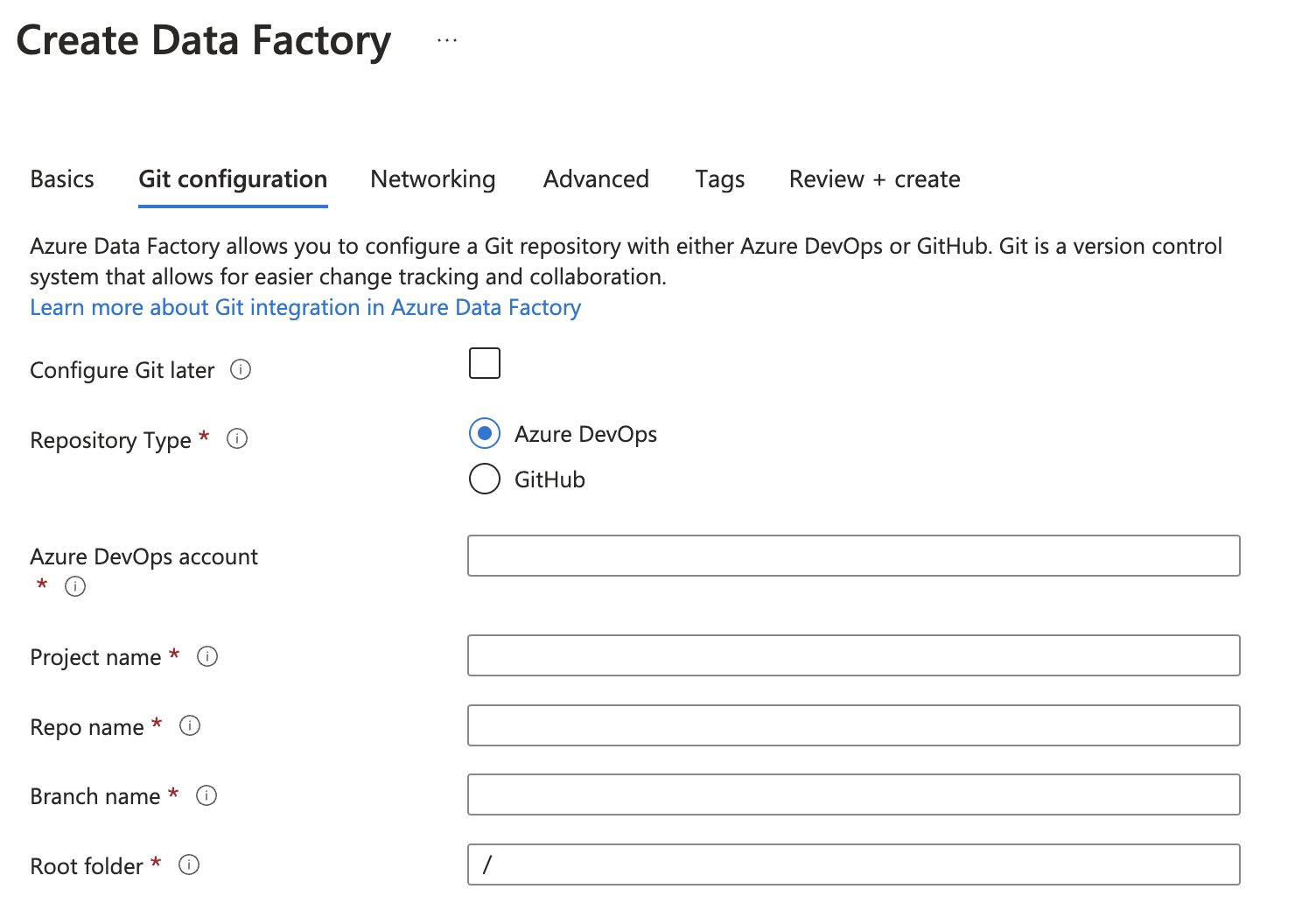
Or after launching the Studio, choose Linked service and set up the git repo
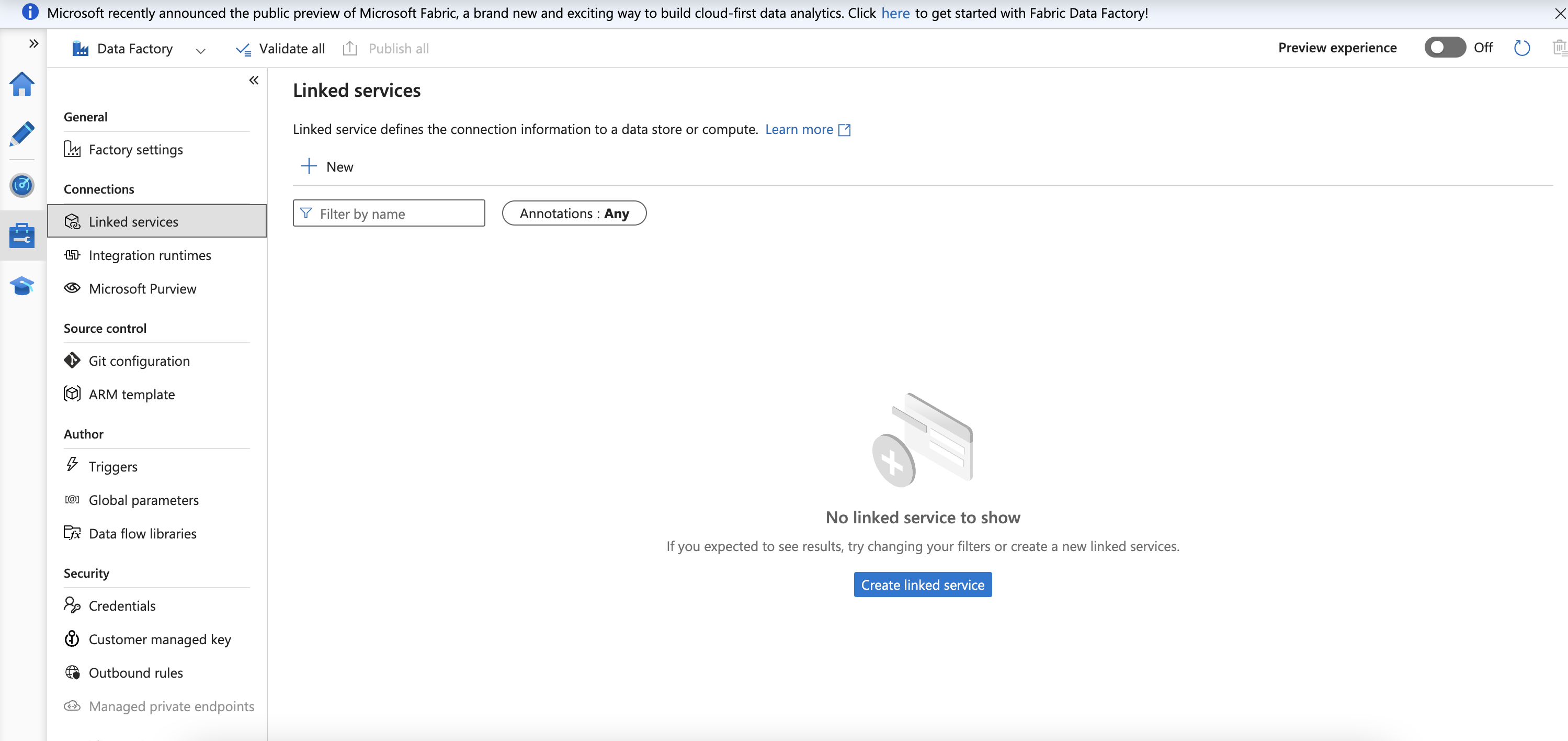
Create pipeline
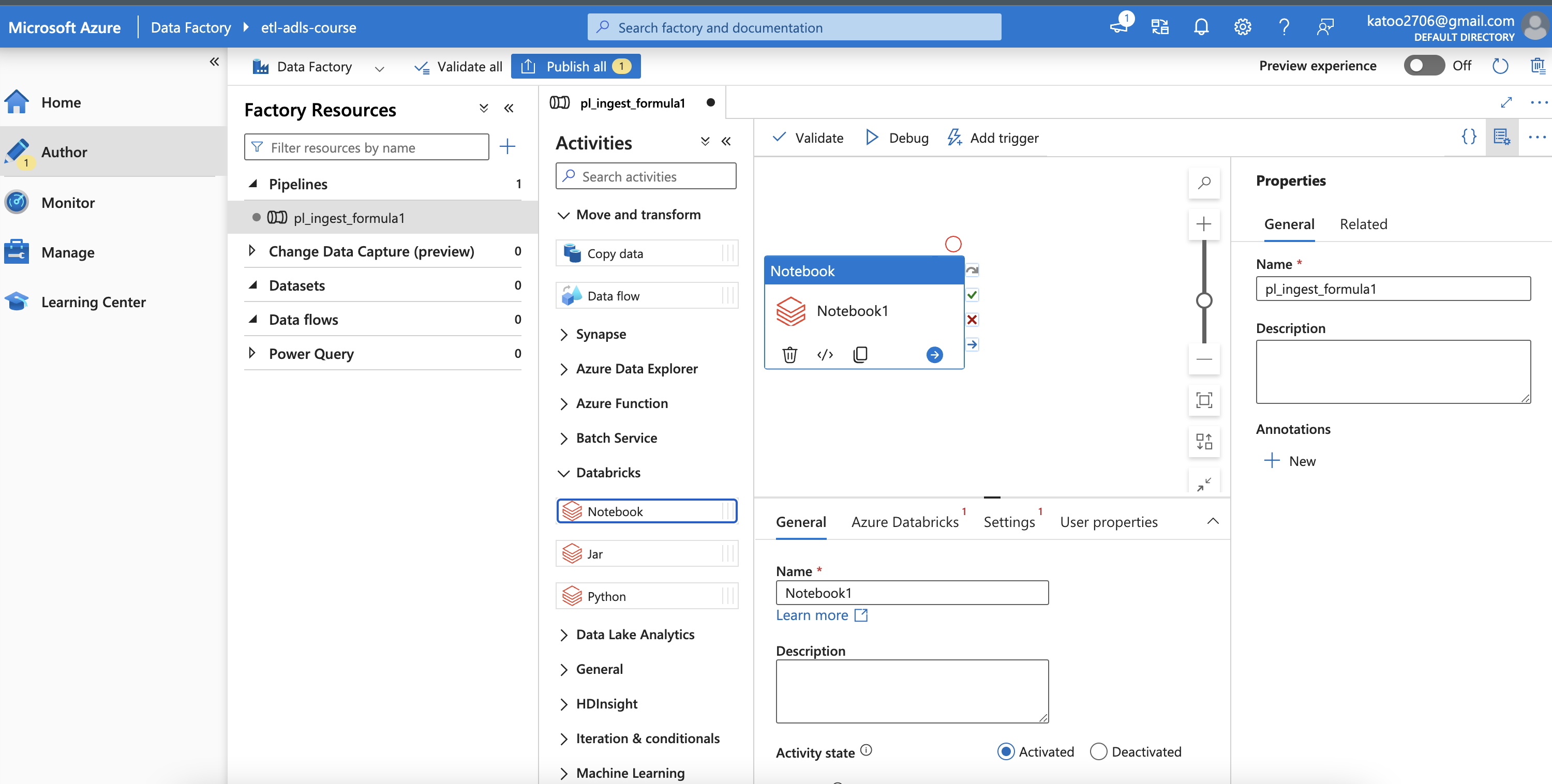
Set up the linked Databrick Notebook
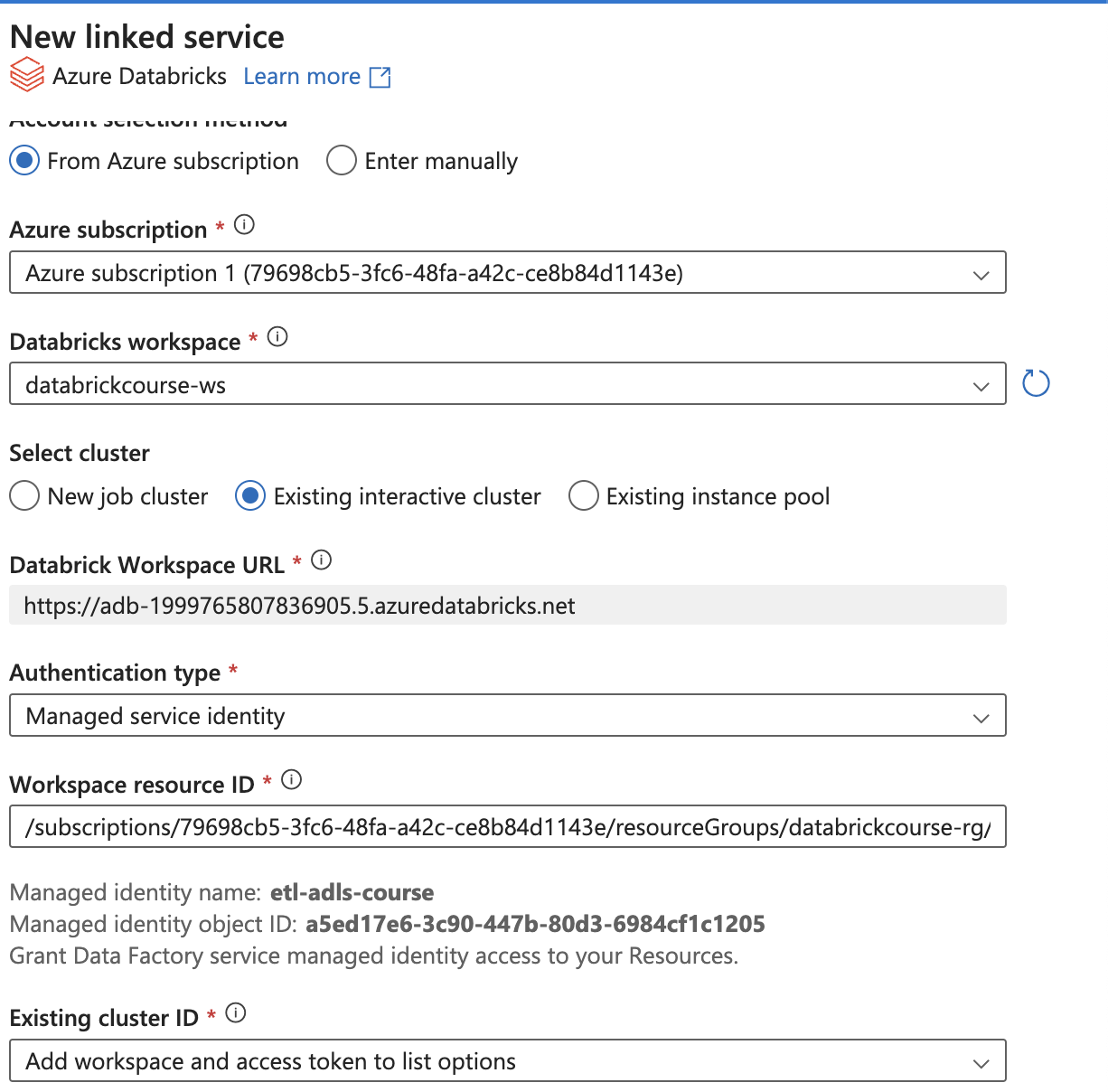
To use Managed Service Identity
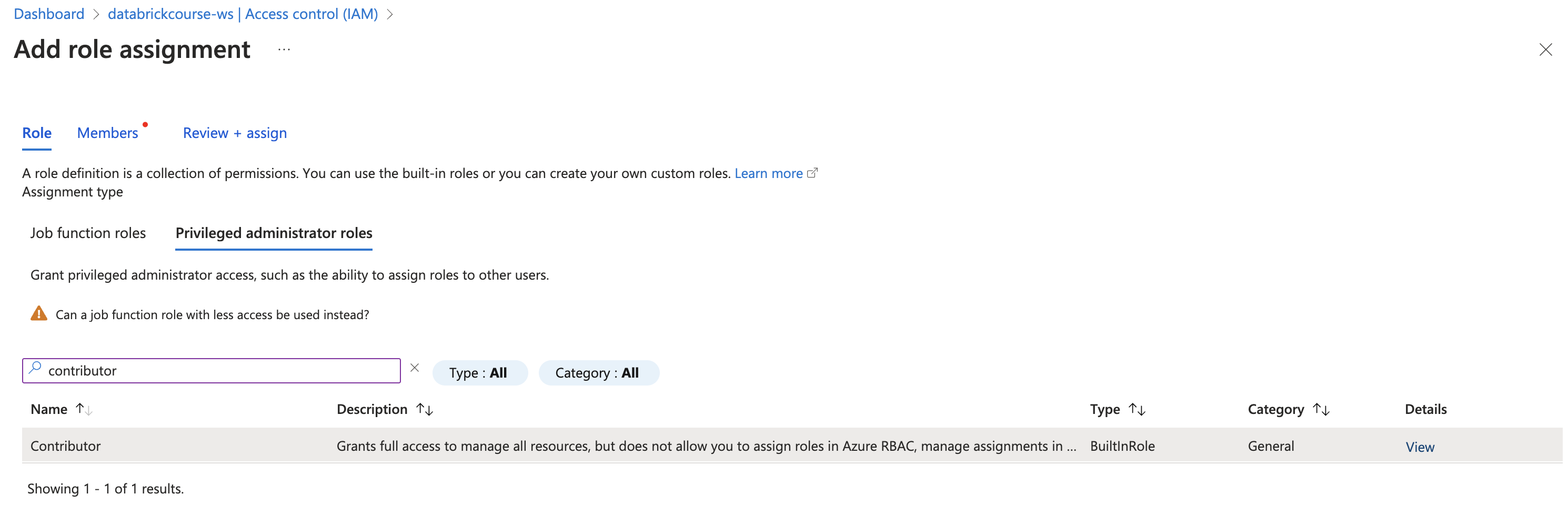
- Change access (IAM) in Azure Databricks Service - workspace
- Privileged Administrator Roles / Contributor
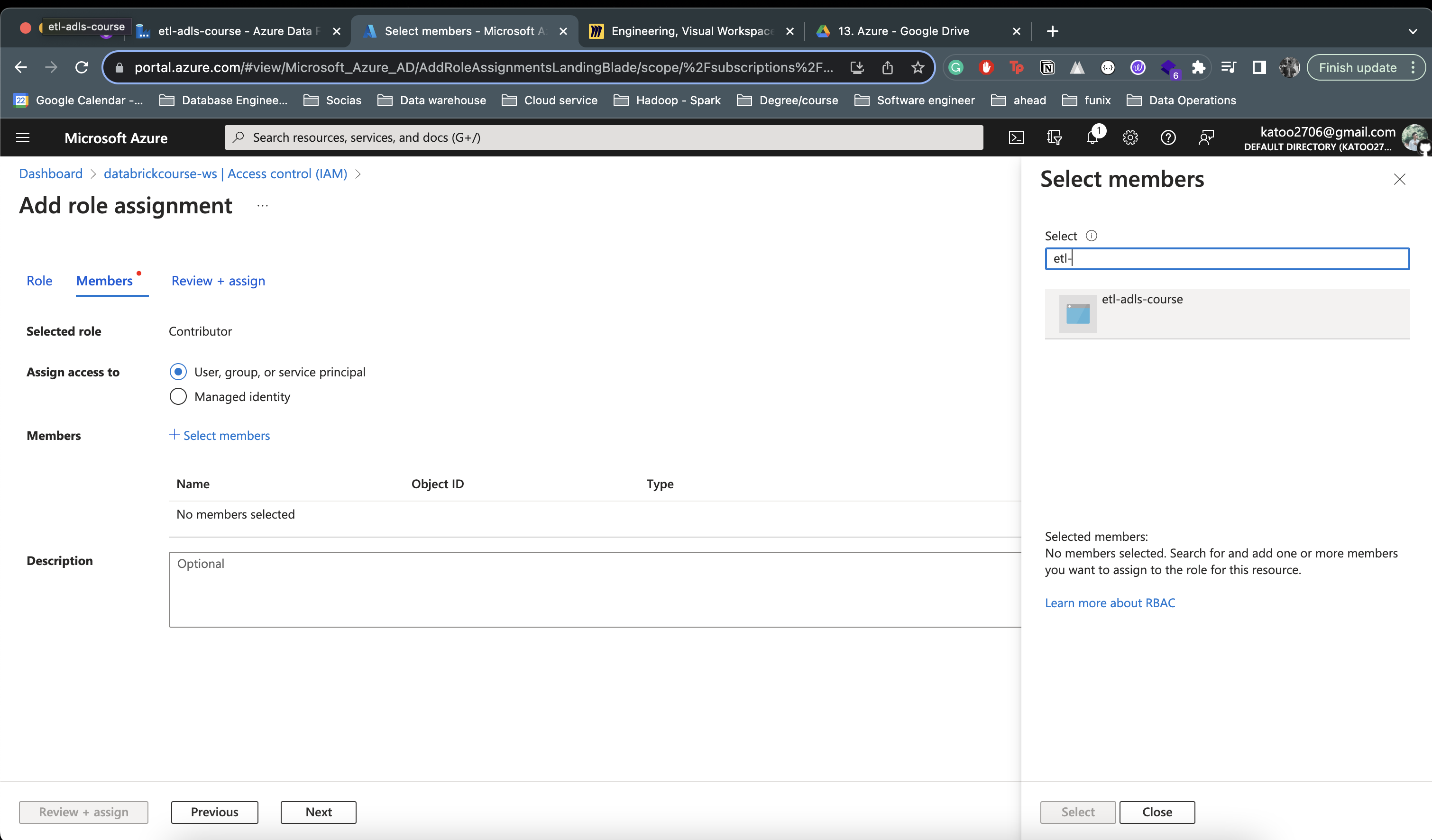
- Add menber etl-adls-course (Data Factory)
-
After that, choose the access from existing cluster
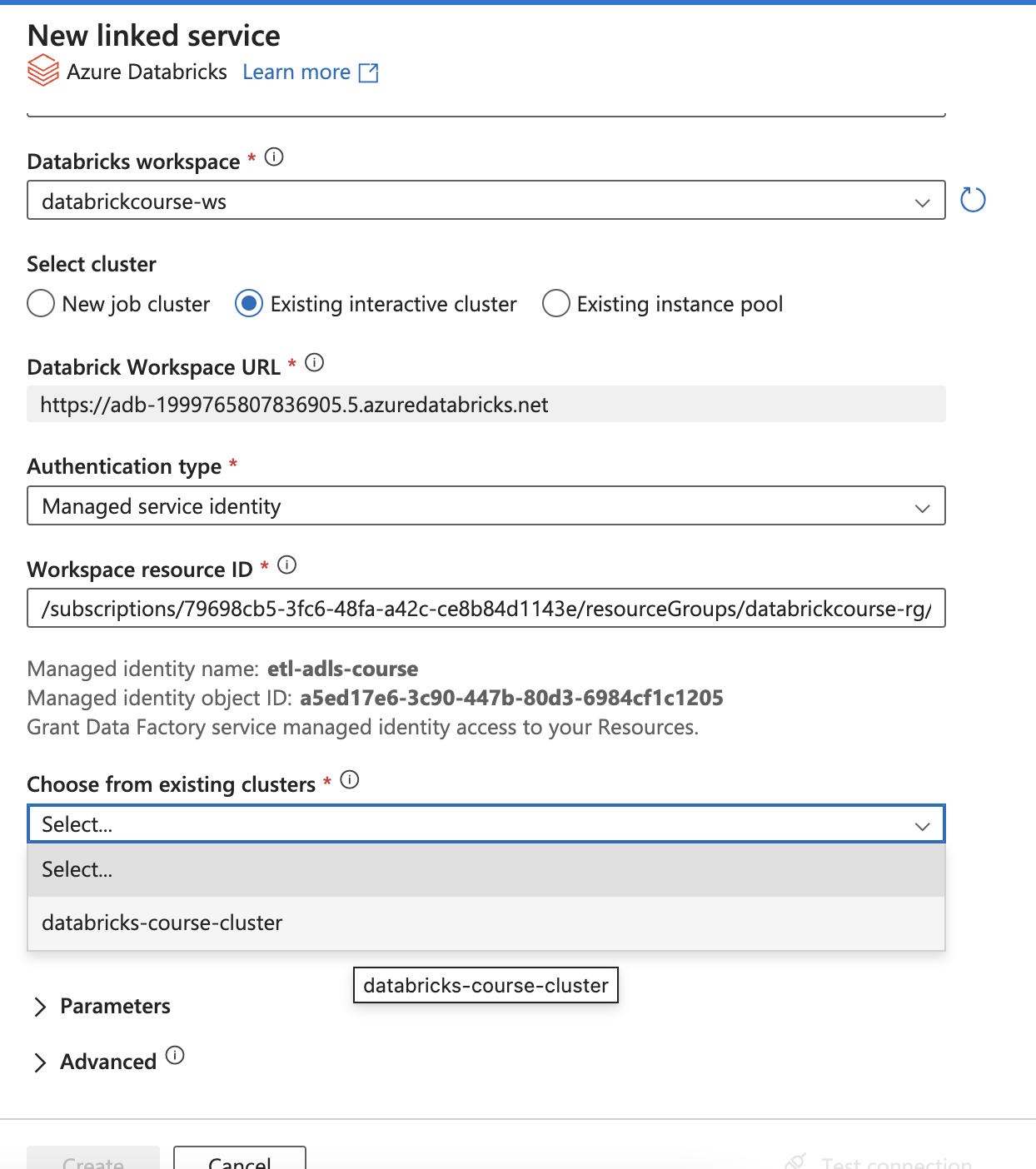 If it’s not loaded, click other cluster and re-click the existing cluster for refresh UI
If it’s not loaded, click other cluster and re-click the existing cluster for refresh UI - Add the dynamic parameters by using Variables from the pipeline
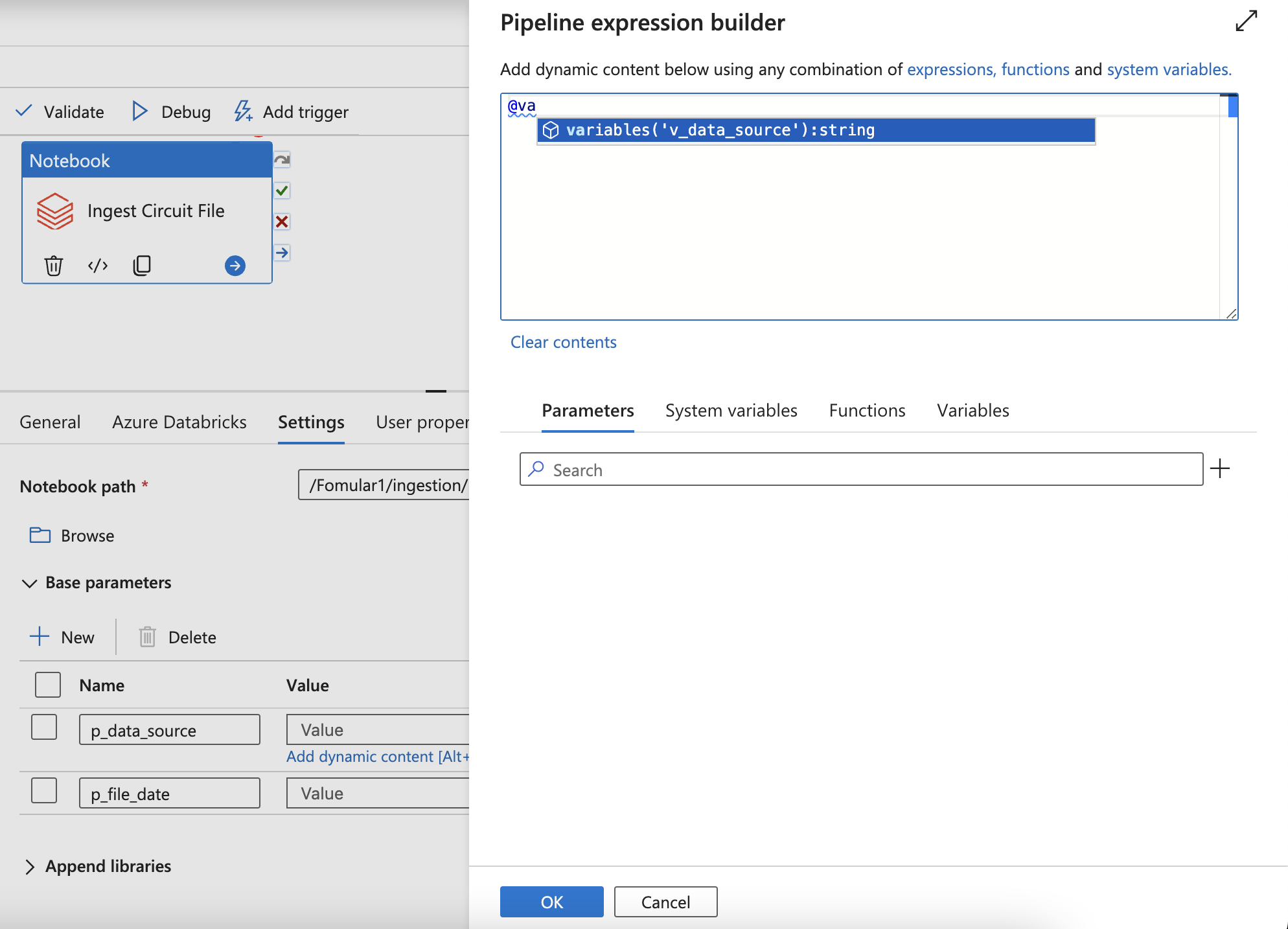
- Or using parameter (Can not be changed)
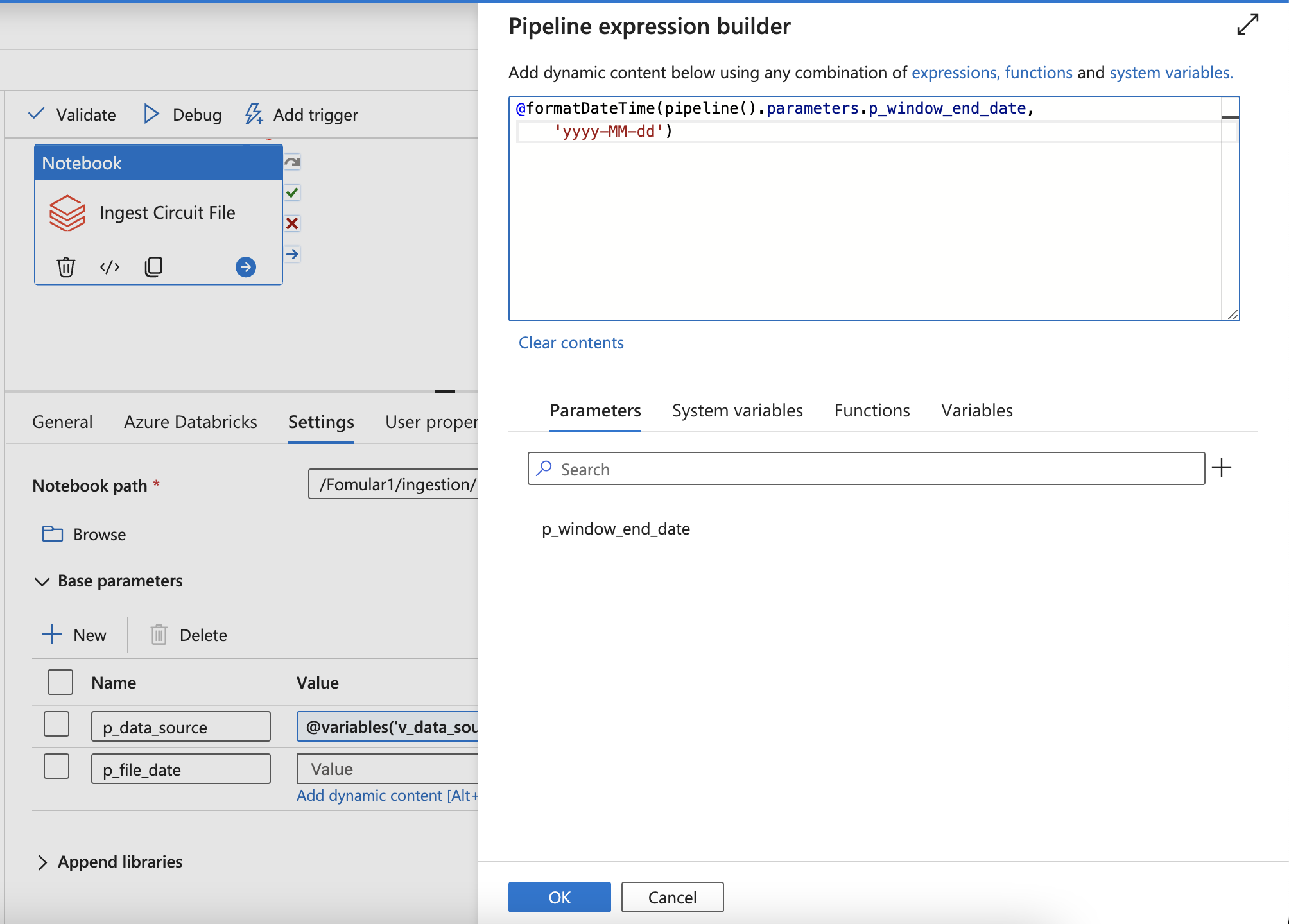
- Config the DAGs
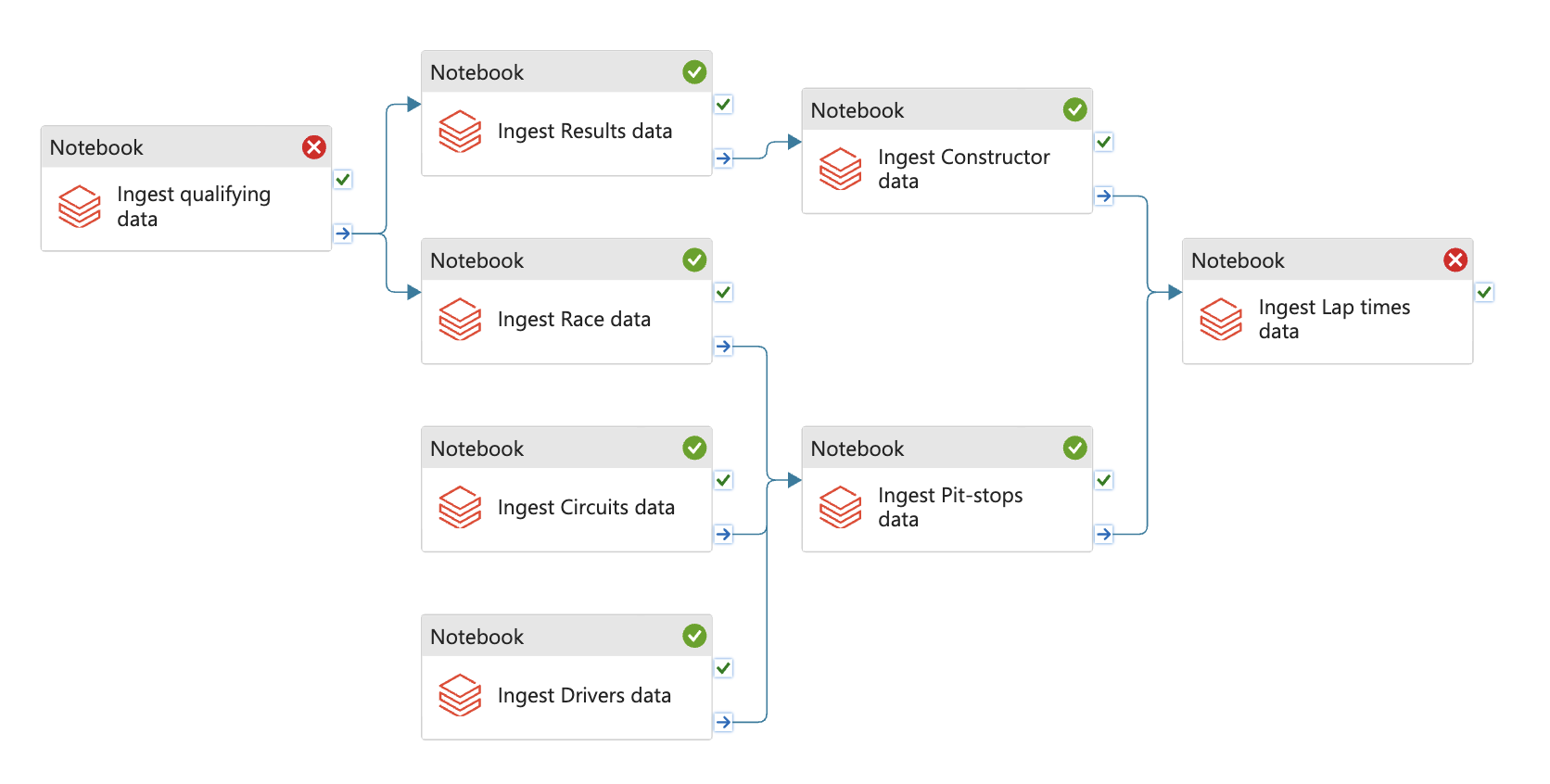
Add Get metadata to check if file exists
| Set up the storage account | Get parameter as directory |
|---|---|
 |
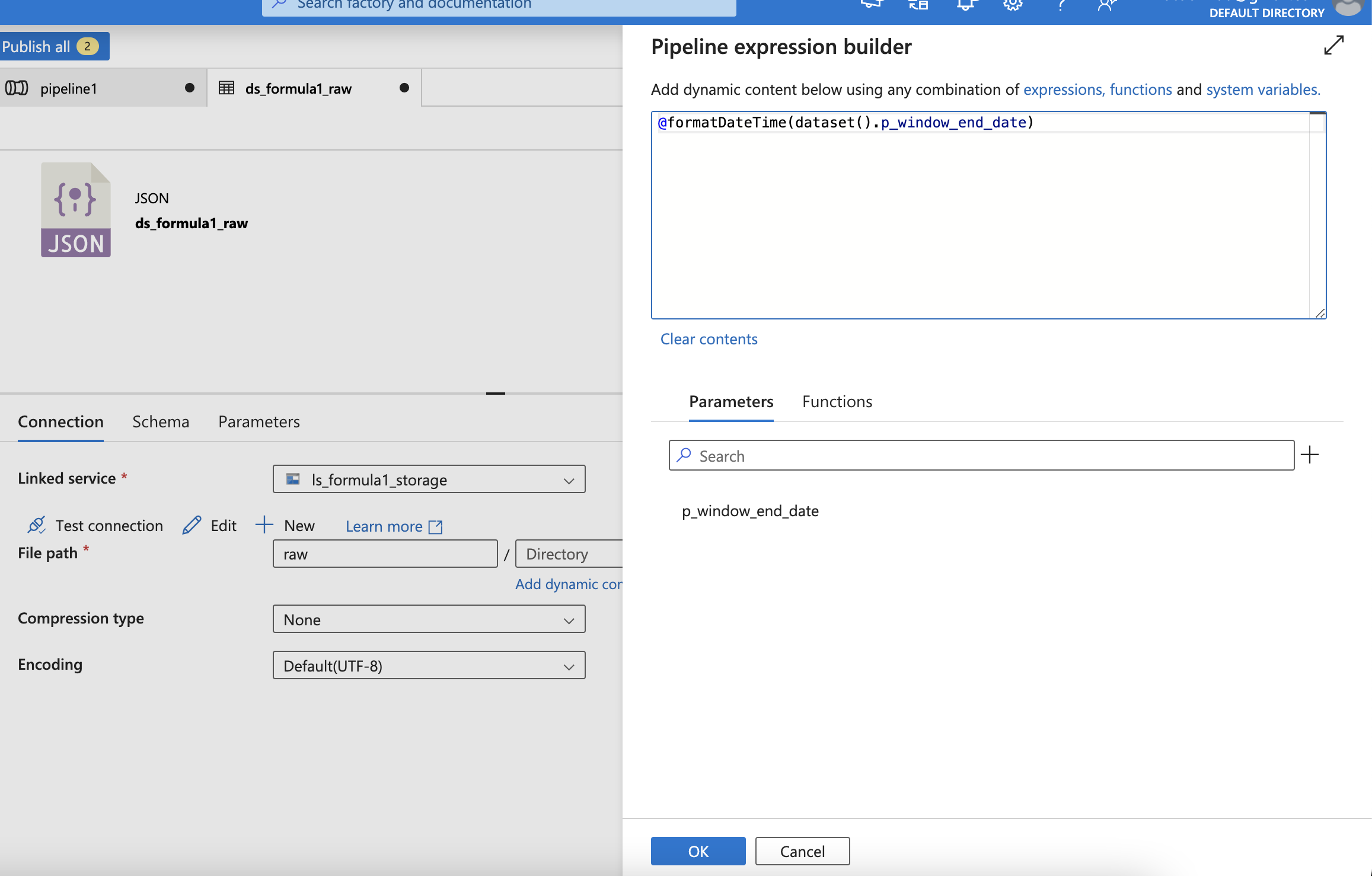 |
Check if data exists or not
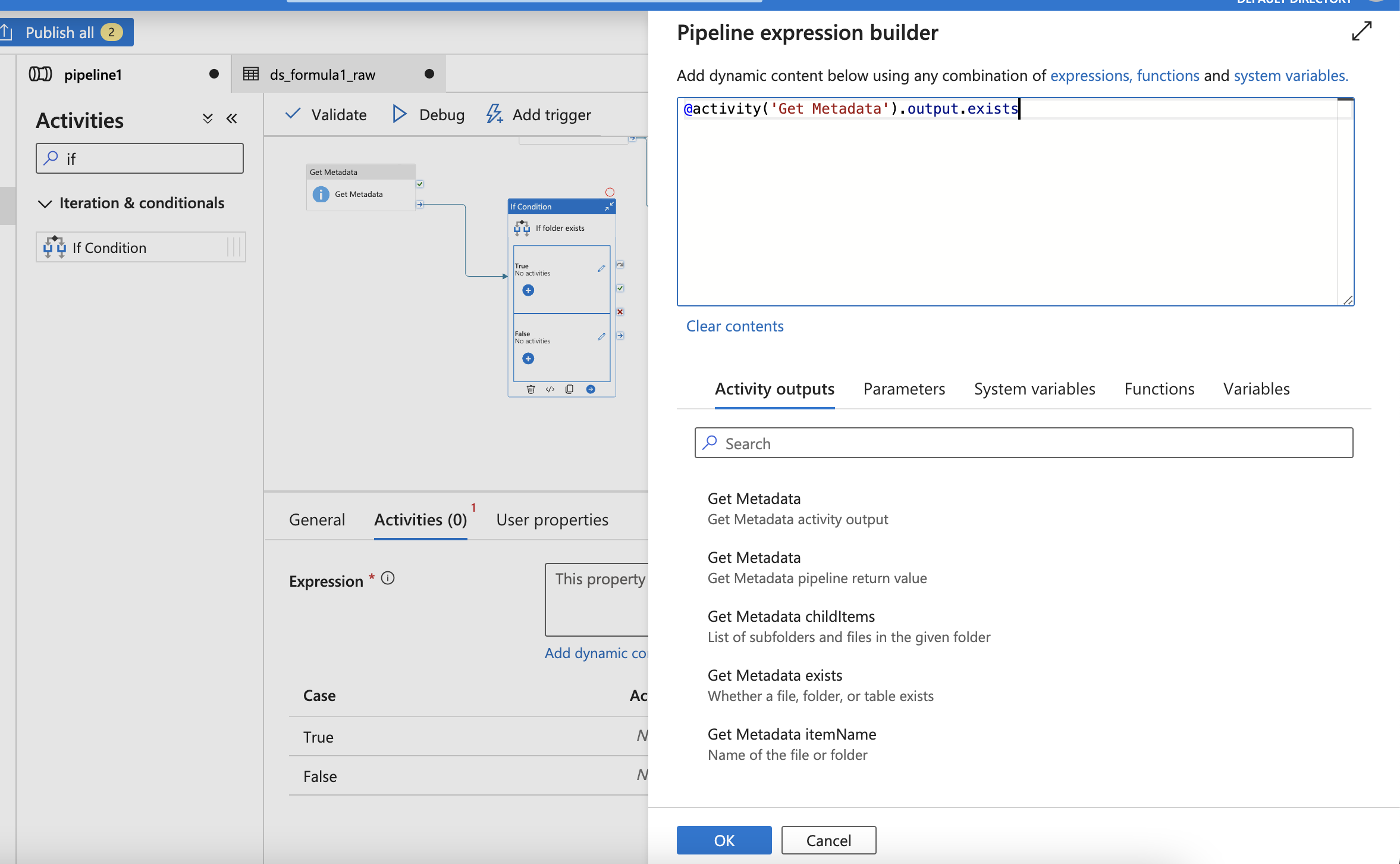
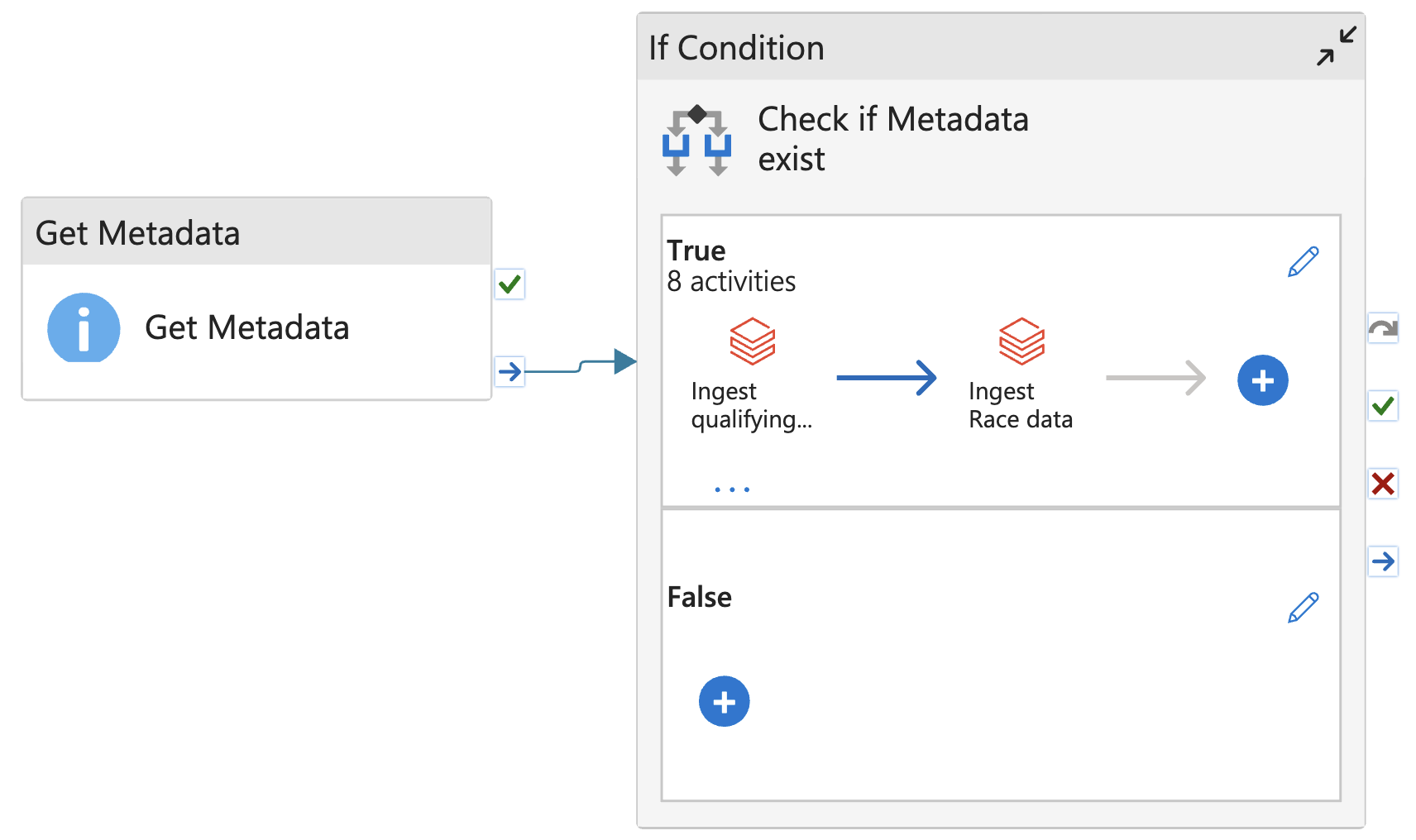
Then, click True (edit) and paste the Notebook into Window
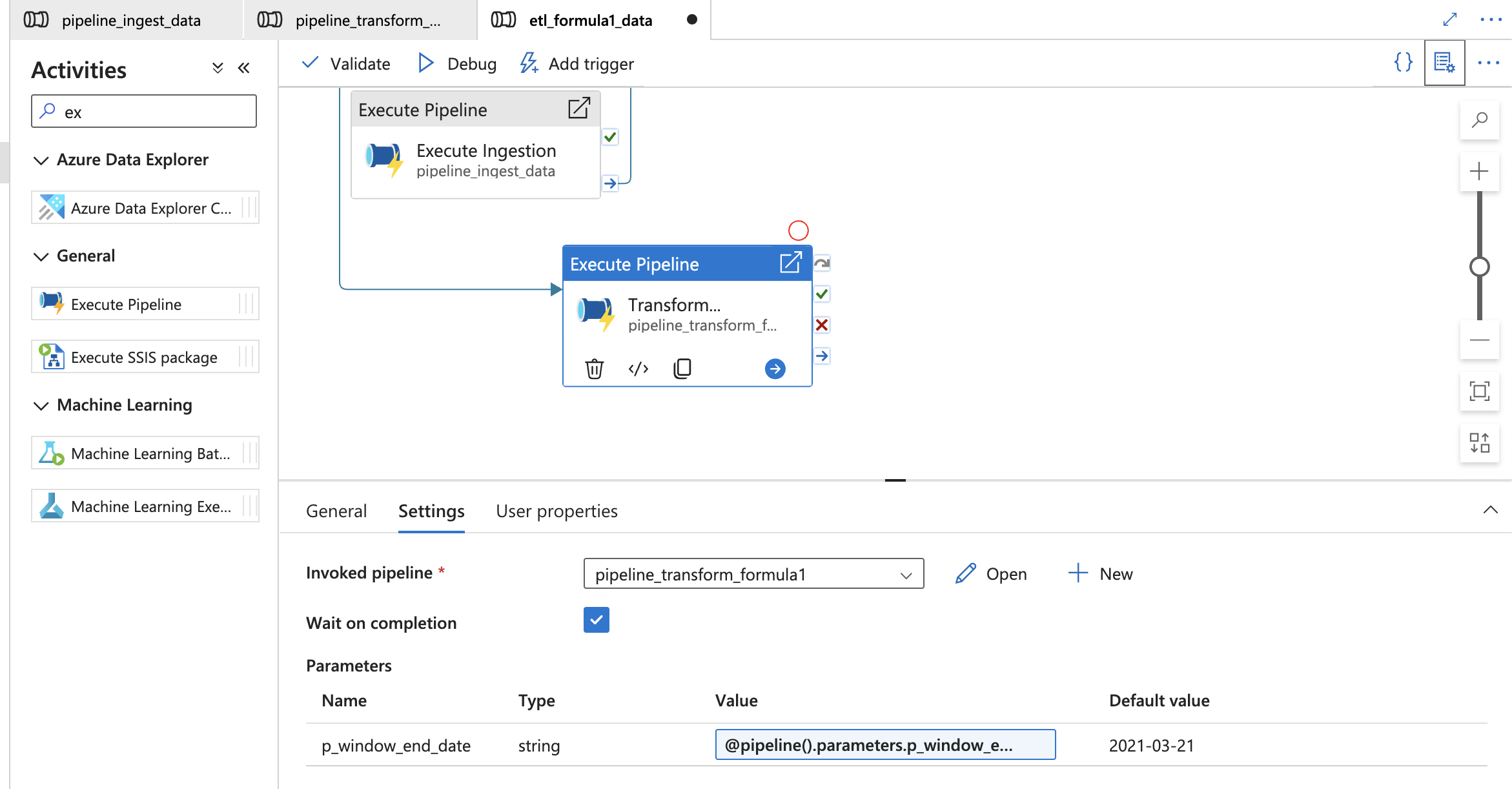
Final: Create master execute pipeline
Updating…
Learn More
For more knowledge about my posts, reach me via [email protected]