Data Catalog & Meta data system in Enterprise
Introduction
In the vast landscape of enterprise data management, it’s surprising to observe that a significant number of organizations operate without a robust data catalog system to effectively store and manage their metadata. This absence of a centralized repository poses several challenges for the enterprise:
-
Onboarding Challenges: The lack of a data catalog makes it challenging for new team members to quickly familiarize themselves with the existing data landscape, leading to potential delays in their productivity.
-
Development and Scaling Difficulties: Without a dedicated data catalog, the development and scaling of data architectures become intricate tasks. The absence of a unified system hampers the seamless integration of data products, making it challenging for data engineers to manage and expand the company’s data infrastructure efficiently.
-
Data Quality Issues: The absence of a centralized data catalog system makes it difficult to enforce and maintain data quality standards. This can result in data inconsistencies, inaccuracies, and overall reduced trust in the organization’s data assets.
When the Data Engineer Steps In
Recognizing these challenges, I took the initiative to build a comprehensive data catalog system. This involved integrating the system with all existing databases, data lakes, data pipelines, and applications within the company’s ecosystem. Furthermore, I played a pivotal role in guiding the development team and business analysts to document their work in this centralized repository. This not only streamlined our internal processes but also set the foundation for improved collaboration and data governance.
Modern Data Catalog System
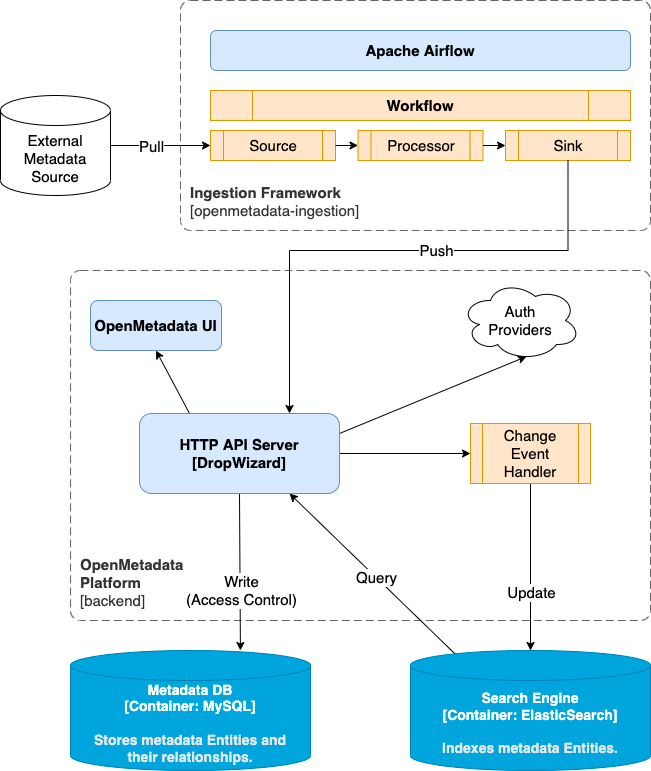 Data Catalog Server Architecture
Data Catalog Server Architecture
OpenMetadata is a complete package for data teams to break down team silos, share data assets from multiple sources securely, collaborate around data, and build a documentation-first data culture in the organization.
Embracing the need for a modern and robust data catalog, I turned to Open Metadata to address our organization’s data management challenges. Open Metadata provides a range of features that make it a cutting-edge solution for enterprises:

Data Discovery
OpenMetadata with a single catalog aggregates metadata about all data assets, and presents the right information to users depending on their needs
Users can search across tables, topics, dashboards, pipelines, ML models, containers, glossaries, and tags.
Data Collaboration
-
Conversations Threads: Collaborate around data assets and tags by asking the right questions and discussing the details right within OpenMetadata.
-
Tasks: Create tasks around data assets to create and update descriptions, request for tags, and initiate a glossary term approval workflow.
-
Announcements: Announce to your entire team about the upcoming events and changes such as deprecation, deletion, or schema changes.
Overview of Data Quality and Profiler
With OpenMetadata, you can build trust in your data by creating tests to monitor that the data is complete, fresh, and accurate. OpenMetadata supports data quality tests for all of the supported database connectors. Users can run tests at the table and column levels to verify their data for business as well as technical use cases.
Data quality.
OpenMetadata provides Data Quality workflows, which helps with:
- Native tests for all database connectors to run assertions.
- Alerting system to send notifications on test failure.
- Health dashboard to track realtime test failure and to prioritize efforts.
- Resolution workflow to inform the data consumer on test resolutions.
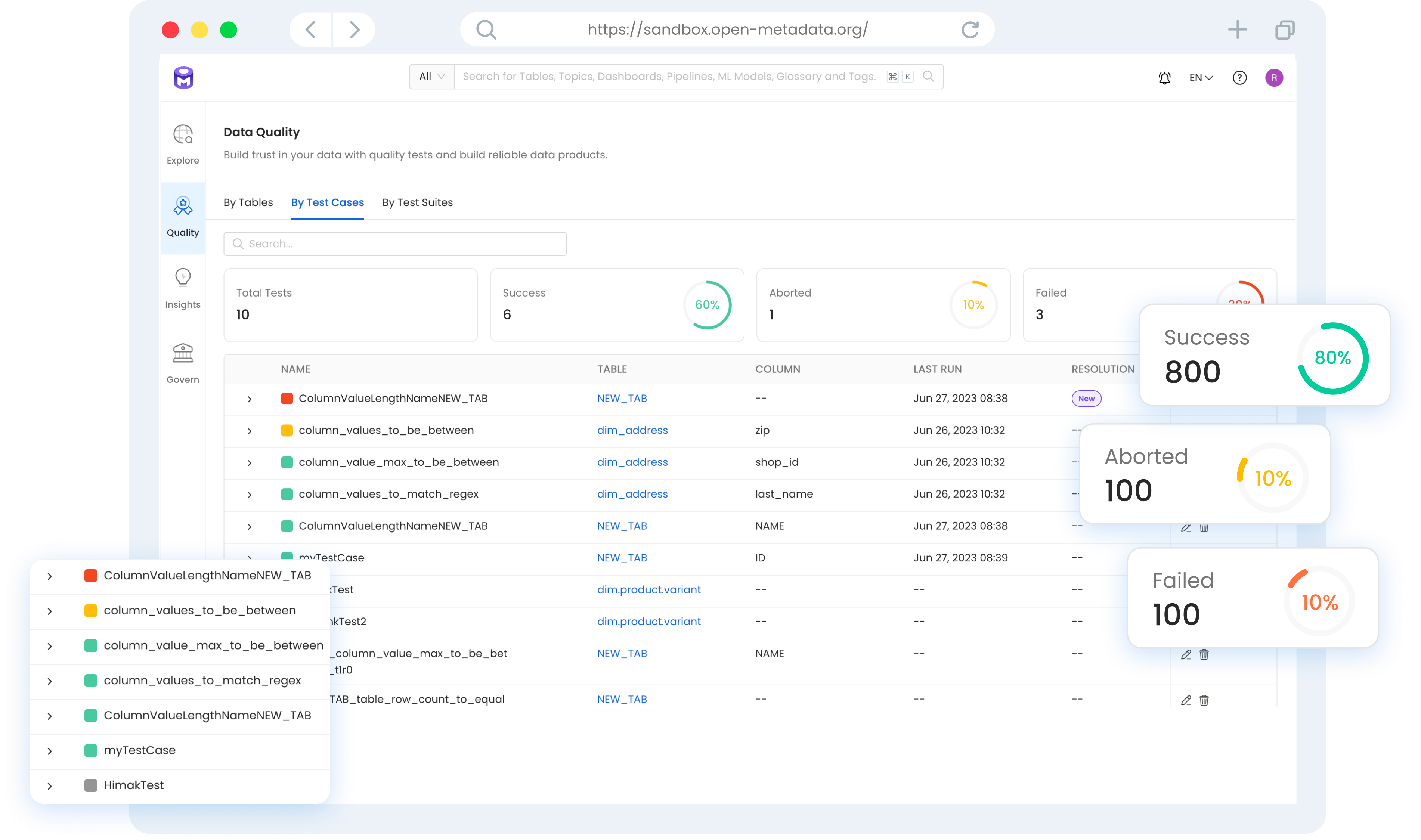
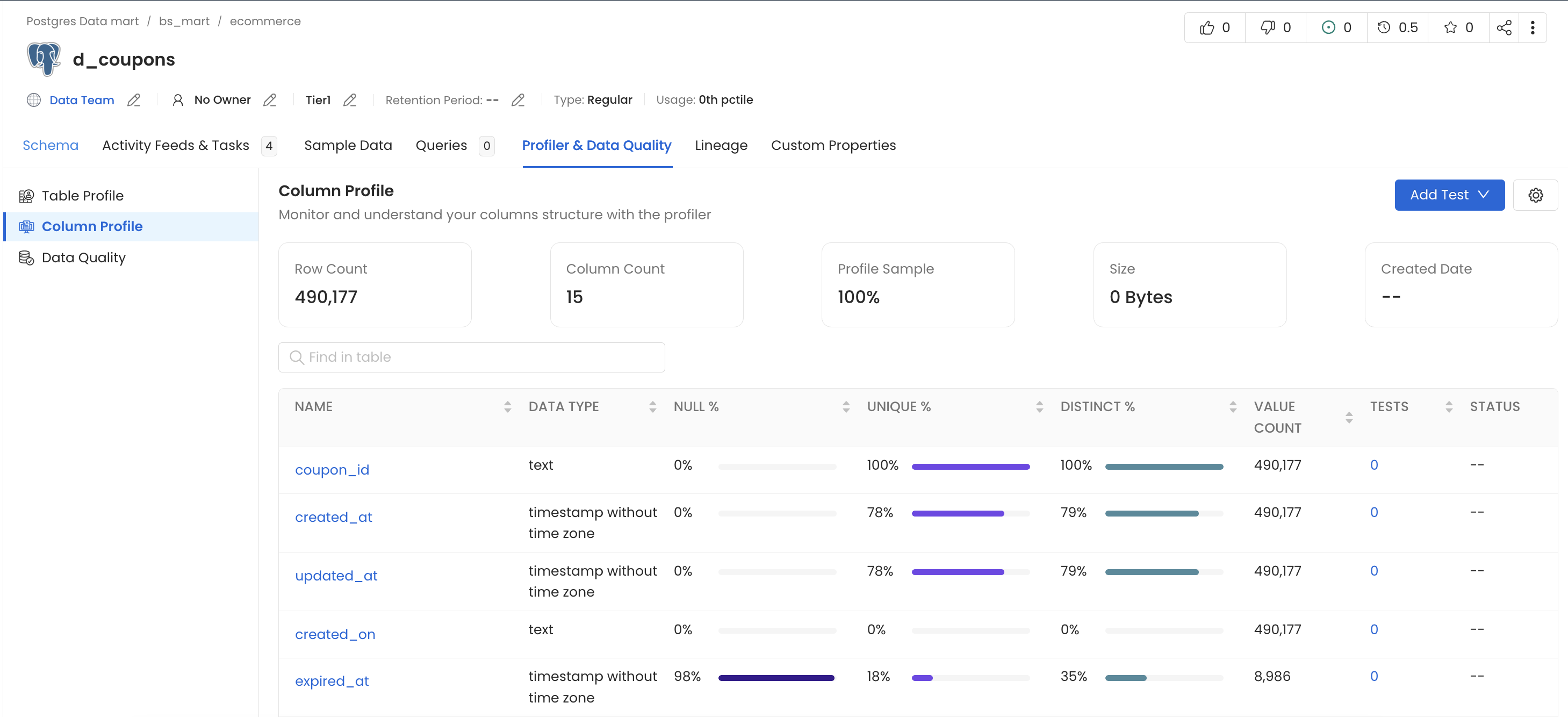
Data profiler
Data profiles enable you to check for null values in non-null columns, for duplicates in a unique column, etc. You can gain a better understanding of column data distributions through descriptive statistics provided.
Data Lineage
Tracks data lineage, showing how data moves through the organization’s systems. Users can visualize how data is transformed and where it is used, helping with data traceability and impact analysis. OpenMetadata supports lineage for Database, Dashboard, and Pipelines.
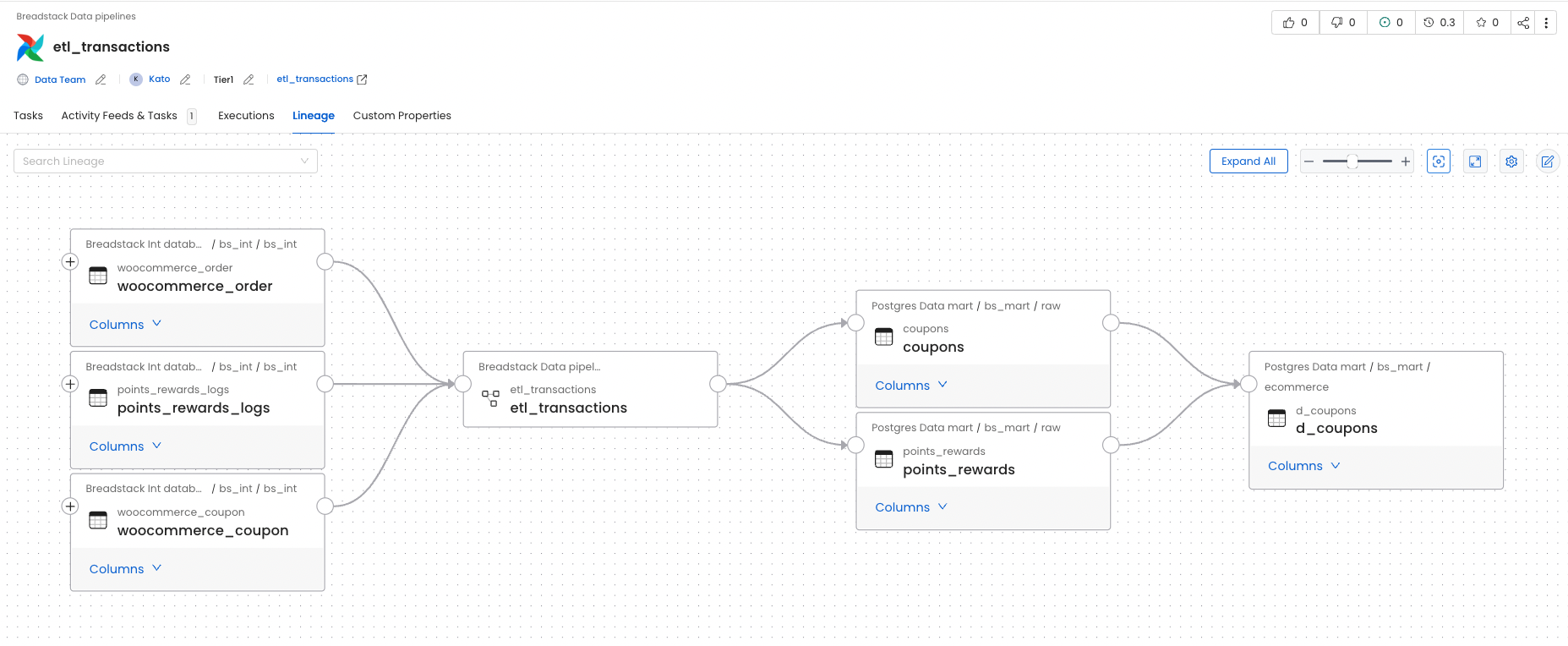 For Example, we can have an explicit view of how data come from data sources to data warehouse
For Example, we can have an explicit view of how data come from data sources to data warehouse
Data Insights
Centralized, active metadata repository where all your data resides. Organizations can drive the adoption of OpenMetadata by monitoring its usage and setting up company-wide KPIs. The built-in goal-setting and tracking mechanisms help proactively drive your company’s data culture. You can define the Key Performance Indicators and set goals to be achieved within a timeframe towards better documentation, ownership, and tiering.
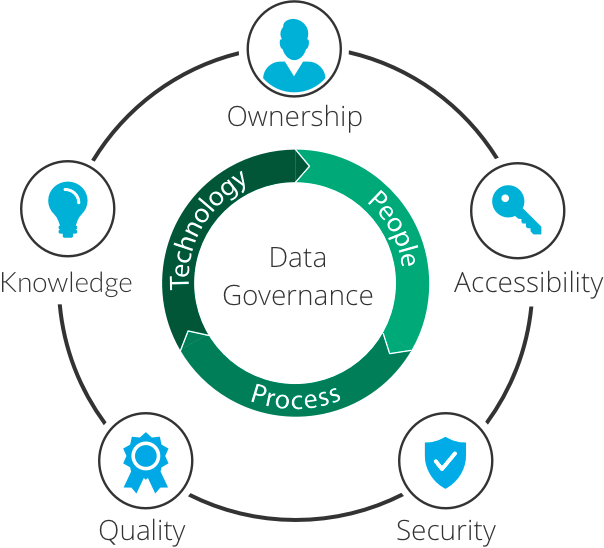
Data Governance
A rich collaborative platform for data teams. Data producers and data consumers can access all their organizational metadata from OpenMetadata. Users can mutually benefit from the team’s collaborative expertise around data. With several teams and users having access to the organizational data assets in OpenMetadata, it is crucial to have some form of governance in place. OpenMetadata supports fine-grained Access Control Roles and Policies to ensure data security.
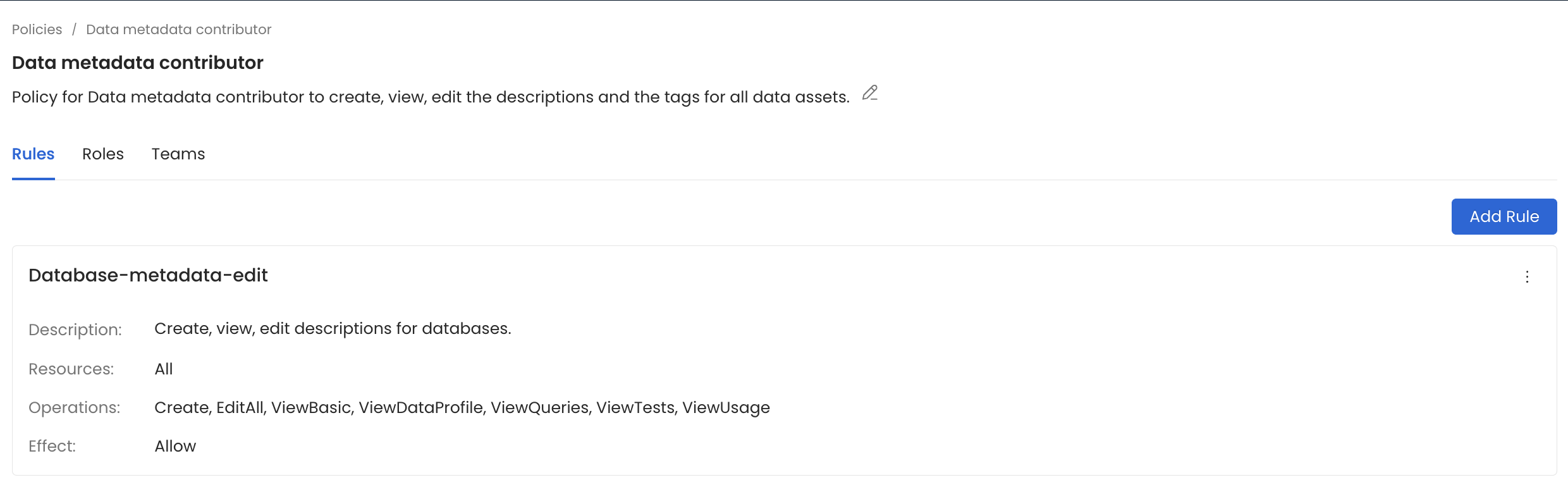
Role Based Access Control
Each role has a defined policy. Policies are composed of a set of rules. Rules allow/deny access to metadata operations such as updating descriptions, tags, owners, and lineage.
For example, users who are assigned to this policy only can contribute tags, descriptions and can not see the data sample & profiler
By leveraging Open Metadata as our data catalog system, we have not only addressed the challenges highlighted earlier but also paved the way for a more efficient, collaborative, and data-driven enterprise.