Sales & Marketing Data warehouse project

Introduction
Project Architecture
Data Architecture Design (by @Kato)
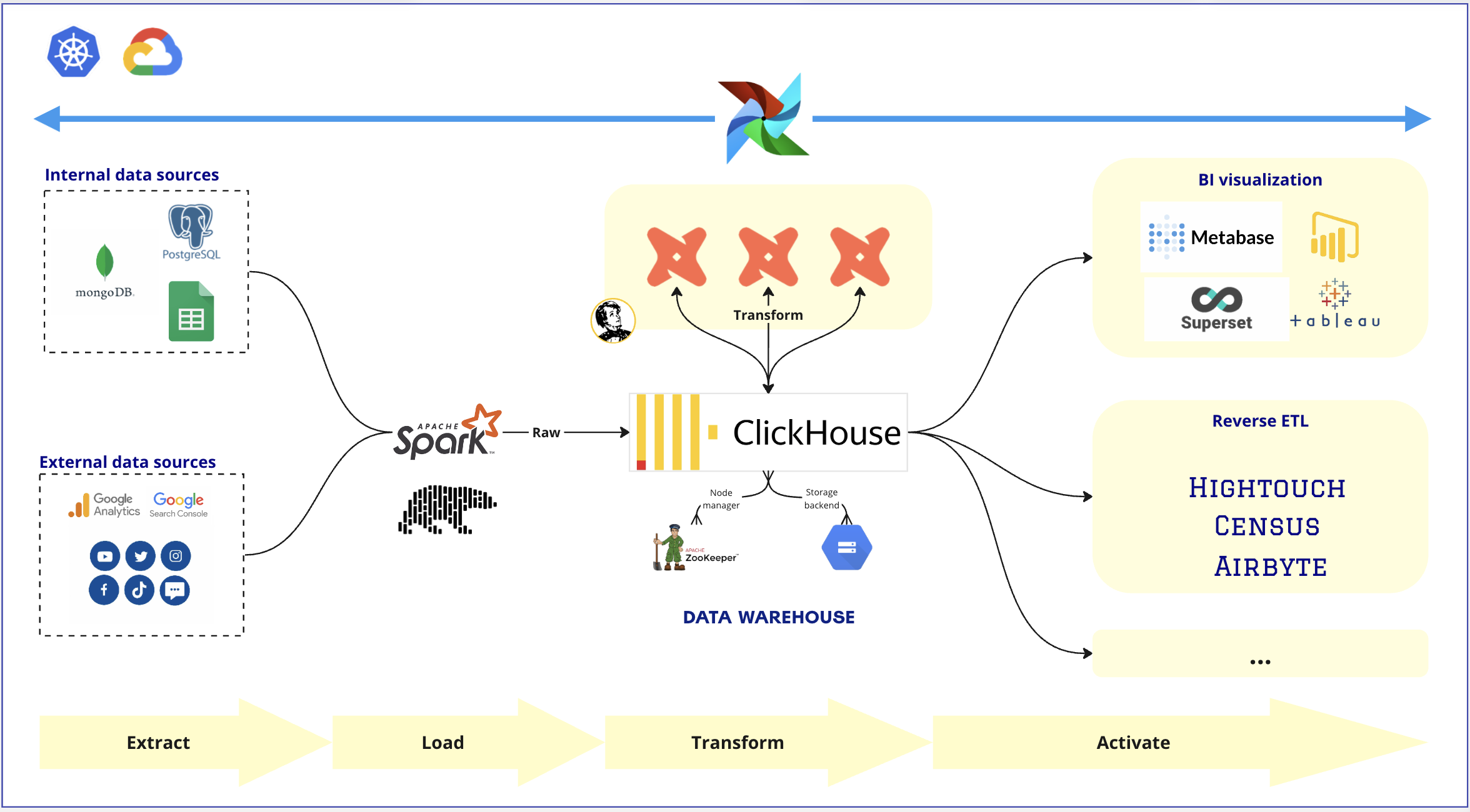
Core Warehouse Design
1. Data Ingestion layer
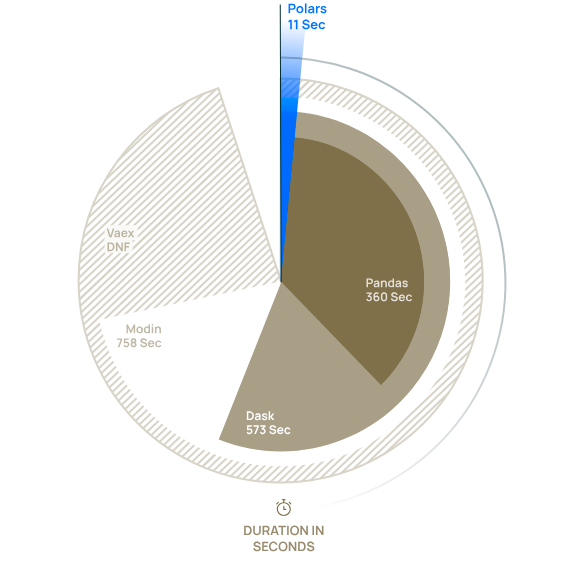
Ingestion framework:Polars with Python to process data on a single machine. Polars is a scalable and efficient framework for handling data and is considered as an alternative to the very popular pandas library.
Compared to pandas, it can achieve more than 30x performance gains.
Moreover, Polars can handle data type and struct fields very well, which could help us a lot to process data from MongoDB.
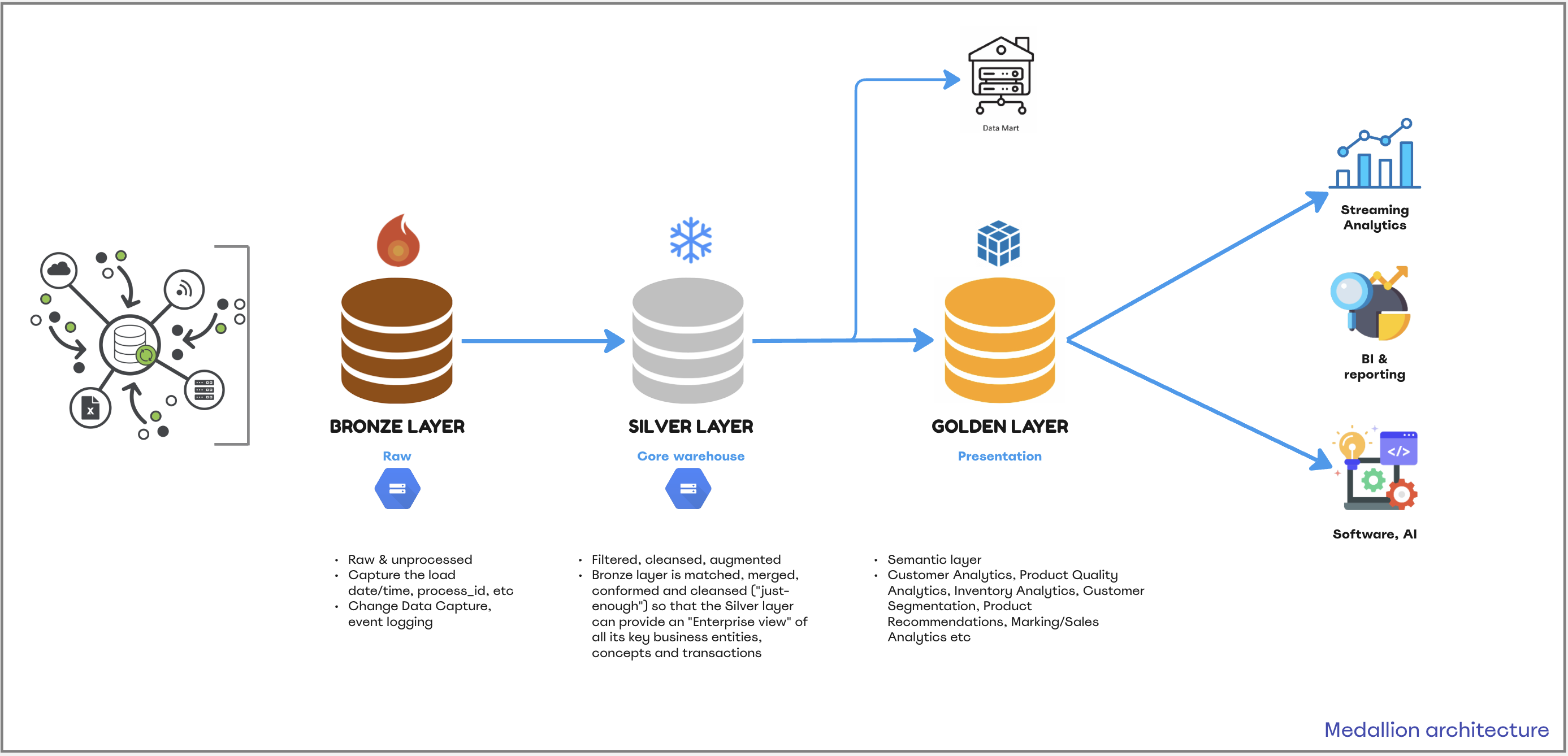
2. Why Medallion architecture?
Before we delve into the architectural decisions, let’s first discuss all data sources and the data sinks. This will provide us with the necessary context to understand the rationale behind these decisions.
Data Sources: Given the project’s scope, data acquisition involves pulling data from both a NoSQL database (MongoDB) and external data sources from the Marketing departments (such as Social channels, GA, etc.). This poses a challenge for Data Engineers when new data fields are introduced.
While MongoDB is an excellent choice for storing software data due to its scalability and extensibility, it lacks consistency. If new fields are added without prior notification, issues arise because the raw database structure differs from the structured database. Although projections can be implemented to prevent this, the preference is to avoid introducing new fields in the data sources altogether.
If changes extend beyond adding fields to altering column names or deleting existing fields, the traditional data warehouse architecture demands rebuilding the entire ETL pipeline. This involves adding new tables, deleting old ones, and renaming to ensure connectivity with BI tools.
Enter the Medallion architecture, a lifesaver in such scenarios. Here’s what you need to do:
- Revise your query from
MongoDB. - Drop raw tables in the raw database and set a checkpoint time for incremental extraction in the logging table.
- Modify the SQL scripts for DBT.
- Re-run the process.
DBTwill automatically adjust the schema structure if new fields arrive with the parameteron_schema_change=sync_all_columns.
3. Airflow running on Kubernetes
We can utilize task_group and chain to design data pipelines, making it easy to manage resources for each phase of the data processing workload.
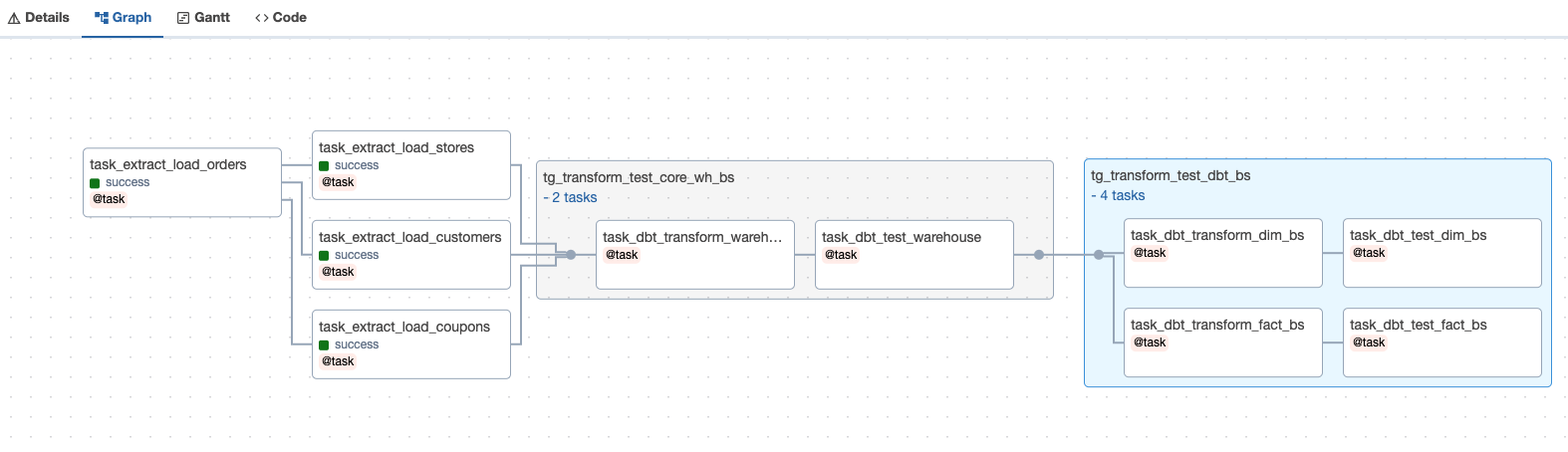
The Kubernetes Executor is an Airflow feature that allows you to execute multiple Airflow tasks in parallel, each within its own isolated environment, using Kubernetes Pods.
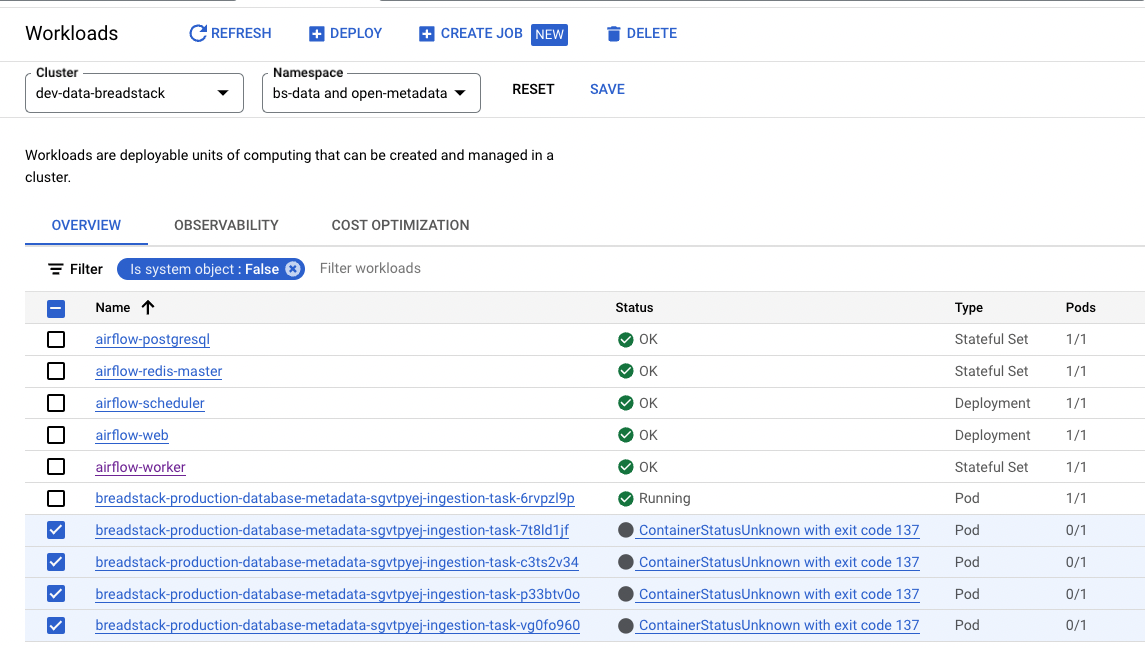
The Kubernetes Executor offers several advantages, including:
Resource isolation and task-level configurations:
Each task runs in an isolated environment, reducing interference between tasks and allowing resources to be specified at an individual task level. This isolation and flexibility enhances security and stability, which are vital for complex workflows.
Cost and resource efficiency:
With the Kubernetes Executor, your web server and scheduler costs remain fixed. However, compared to the celery executor, the dynamic scaling of task instance pods allow you to shed the fixed cost of having a celery worker up for 24 hours a day.
No interruption to running tasks:
Some tasks, like machine learning tasks, are expensive to restart. Kubernetes considers nodes with running task instance pods as unsafe to evict, meaning you can reliably run 24-hour or longer workloads.
Cluster Orchestration:
With the Kubernetes Executor, Airflow can distribute tasks across a Kubernetes cluster, enabling parallel execution and faster completion of data pipelines.
Reference: https://www.astronomer.io/blog/leveraging-apache-airflow-and-kubernetes-for-data-processing/
This approach ensures
clarityandtransparencywhen maintaining data pipelines, and fault tolerance.
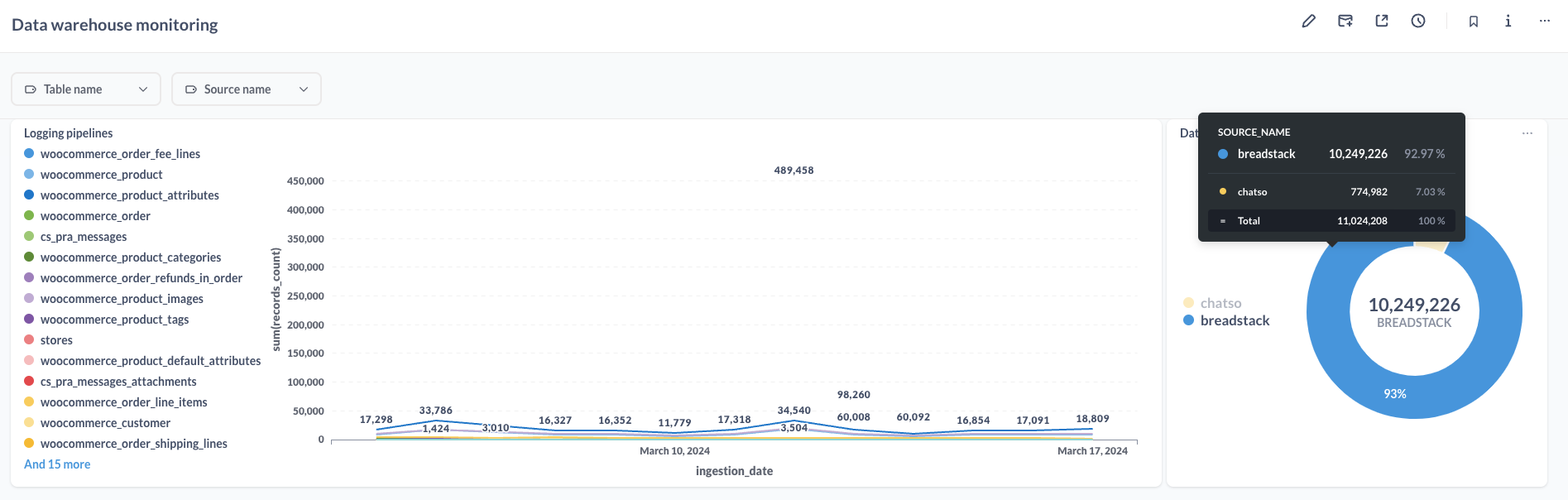
4. Monitoring the data pipelines
For this project, I’ve built an ETL subsystem to monitor the data pipeline, to:
- Manage data throughput, by data sources / tables.
- Troubleshoot any failures occurring daily.
For example:
What’s else?
Updating…
Learn More
For more knowledge about my posts, reach me via [email protected]