Human Resources Data warehouse project
Great purposes:
- Developed a robust data collector using Streamlit application and a Cloud Database.
- Designed and managed a non-relational staging database to ingest data from
Jira(Track recruitment activities),Humi,1Office, and performed web scraping from the Breadstack career site. - Successfully tested and integrated data from additional sources (
Trello,Snipe-it,LinkedIn Jobs) - Implemented a Postgres data warehouse for the HR project to make unified Human resources data model.
- Developed extract, transform, and load (ETL) pipelines to move data from various sources to staging, and from staging (including Streamlit app) to the data warehouse.
Architecture
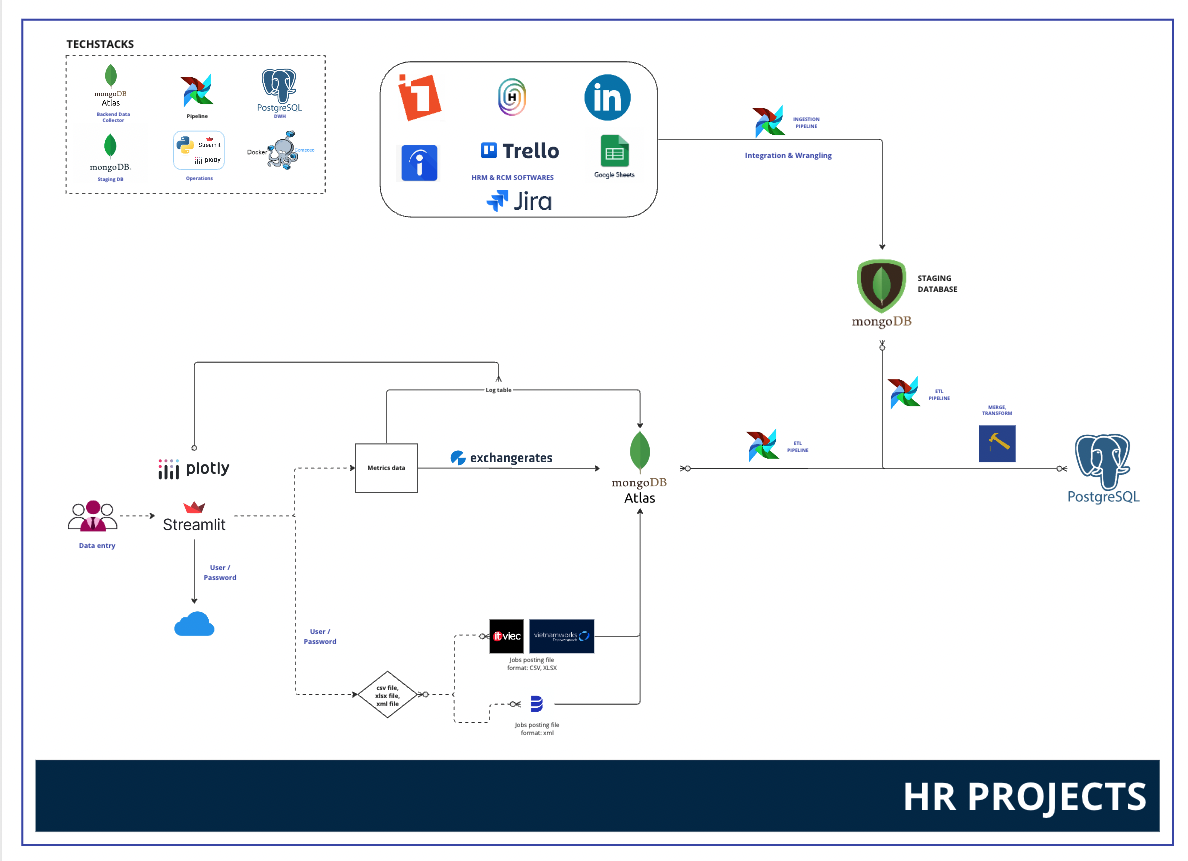
Data warehouse model
Data Collector Application
Streamlit,plotly,deta space
In this project, I use Streamlit to develop a Data Collector Application to gather metrics data from Business user.
Data from Data Collector will be stored in Cloud Database (Mongo Atlas)
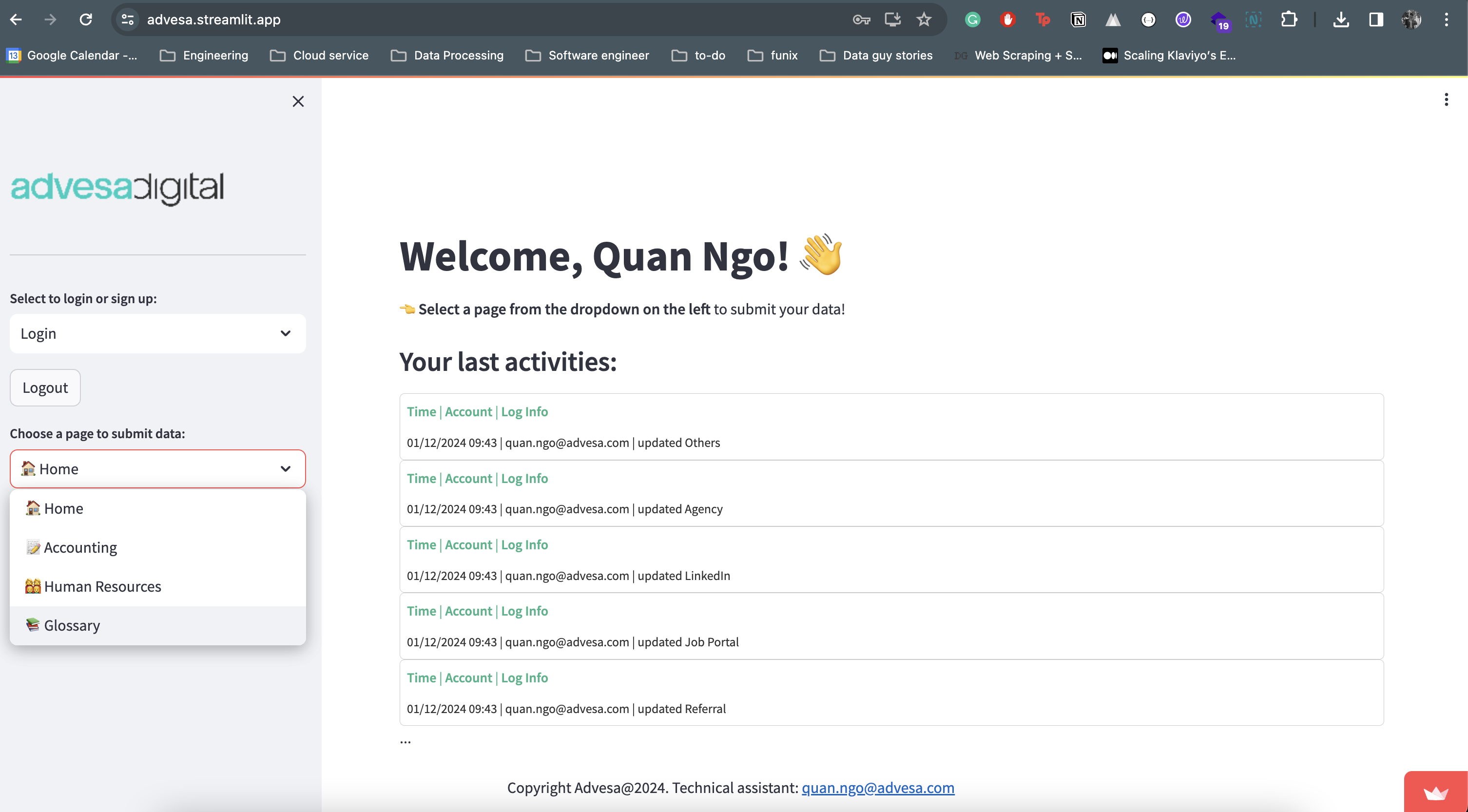
Staging Area
NoSQL Database:
MongoDB
Use Pymongoarrow to read data from MongoDB and take advantages of Pandas-struct field.
Using non-structured database for staging area will take the advantages of data retrieval from different data sources and we don’t need to take time to ensure the data source structure. On the other hand, It can make the extract and load process will be fault tolerance and easy to scale.
Learn More
For more knowledge about my posts, reach me via [email protected]
This post is licensed under
CC BY 4.0
by the author.