Spark Streaming 3 and Integrate with Kafka, JDBC, Cassandra with Scala

Introduction
In this personal project, I am using Scala to leverage Spark Structured Streaming.
- Read stream data from socket, using
Netcatto create a local socket and input data - Read stream data from a
Kafkatopics. - Read stream data from
folders - Write data to
Socket,Kafka topics,Cassandra,Postgres
Tech usages: Netcat, Apache Kafka, Apache Spark, Cassandra, Scala
Git repo: ![]()
General Concepts:
Structured Streaming Programming Guide
1. Lazy evaluation: Transformations and Actions:
- transformations describe of how new DFs are obtained
- actions start executing/ running Spark code
2. I/O
Input sources:
Method: readStream
- Kafka (Have many sources and have topics as output sink), Flume
- A distributed file system
- Sockets: (Kafka, Flink, Pulsar, MQTT (Message Queuing Telemetry Transport), Nifi)
Output sinks:
Method: writeStream
- A distributed file system
- databases
- Kafka
- Testing sink e.g. console, memory
3. Streaming Output modes
- append = only add new records
- update = modify records in place <- if query has no aggregations, equivalent will apend
- complete = rewrite everything
4. Triggers = when new data is written
- default: write as soon as current micro-batch has been processed
- once: write a single micro-batch and stop
- processing-time: look for new data at fixed intervals
- continuous (currently experimental)
1. Streaming DataFrame Join
- Join data in micro-batches
- Structure Streaming join API
Create trigger for streaming pipeline
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import org.apache.spark.sql.streaming.Trigger
import scala.concurrent.duration._
def demoTriggers() = {
val lines: DataFrame = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 12345)
.load()
// write lines DF as a certain trigger
// fetch batch data retrieval in every 2 seconds (mini-batch)
lines.writeStream
.format("console")
.outputMode("append")
.trigger(
// Trigger.ProcessingTime(2.seconds) // can use "2 seconds"
// Trigger.AvailableNow() // Single batch, then terminate
Trigger.Continuous(2.seconds) // every 2 seconds create a batch
)
.start()
.awaitTermination()
}
demoTriggers()
Restricted joins:
- Stream joining with static: RIGHT outer join/FULL outer join/ RIGHT semi not permitted
- Static joining with stream: LEFT outer join/FULL outer join/ LEFT semi not permitted
- Stream joining with Stream:
- inner join optionally with a watermark
- left/right outer join ONLY with a watermark
Dataset Stream
- Same DS Conversion as non-streaming DS
- Streaming DSs support functional operators
- Tradeoffs:
- pros: type safety, expressiveness
- cons: potential perf implications as lambdas can not be optimized
Low-level Streaming (Discretized stream - DStreams)
This is deprecated as of Spark 3.4.0. There are no longer updates to DStream and it’s a legacy project. There is a newer and easier to use streaming engine in Spark called Structured Streaming.
You should use Spark Structured Streaming for your streaming applications.
2. Spark Streaming Integrations
Spark & Kafka integration: Reference
Kafka & Spark Structured Streaming
Kafka is an open-source distributed streaming platform => make real-time event-driven applications
Image: Wurstmeister / Bitnami
Compare: https://dev.to/optnc/kafka-image-wurstmeister-vs-bitnami-efg
1. Start the kafka topic
Till now, the Kafka cluster is up and running. Now, let’s create a Kafka topic:
- replication-factor: 1 (Allows automatic fail over to these replicas when a server in the cluster fails - recommend 2 / 3)
- partition: 1 (The partition count controls how many logs the topic will be sharded into)
Messages in Kafka are saved into category/feed_name (topics), topics are same as tables in Kafka database. Each message is a record in the database.
1
2
3
4
5
6
7
8
docker exec -it [kafka_container_id] bash
# Command shell script will be in this folder
cd opt/kafka_2.13-2.8.1/
# Create Kafka topic in Kafka container
bin/kafka-topics.sh --bootstrap-server broker_host:port --create --topic my_topic_name \
--partitions 20 --replication-factor 3 --config x=y
Otherwise, use the shell kafka-topic.sh directly. Example for Wurstmeister
1
2
docker-compose exec -it rockthejvm-sparkstreaming-kafka \
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic rockthejvm --partitions 1 --replication-factor 1
2. Create Producer (Publish message to Kafka / Write events into topic)
1
2
# Open a socket and write events
kafka-console-producer.sh --broker-list localhost:9092 --topic rockthejvm
Then run the spark app to consume events from topics
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def readFromKafka() = {
// https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html
val kafkaDF = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092") // ("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subcribe", "rockthejvm") // topic to read data, can have multiple topics, split by comma ("rockthejvm, topicb")
.load()
kafkaDF.writeStream
.format("console")
.outputMode("append")
.start()
.awaitTermination()
}
readFromKafka()
3. Output sink on console
For simple message, by default, value will be Binary Hello Spark, I am an idiot Kafka
1
2
3
4
5
+----+--------------------+----------+---------+------+--------------------+-------------+
| key| value| topic|partition|offset| timestamp|timestampType|
+----+--------------------+----------+---------+------+--------------------+-------------+
|NULL|[48 65 6C 6C 6F 2...|rockthejvm| 0| 0|2024-01-11 11:04:...| 0|
+----+--------------------+----------+---------+------+--------------------+-------------+
Therefore, we need to convert binary to string with select statement
1
2
3
4
5
6
7
8
9
10
kafkaDF
.select(col("topic"),
expr("cast(value as string) as stringValue"),
col("timestamp"),
col("timestampType"))
.writeStream
.format("console")
.outputMode("append")
.start()
.awaitTermination()
-> Output sink
1
2
3
4
5
+----------+--------------------+--------------------+-------------+
| topic| stringValue| timestamp|timestampType|
+----------+--------------------+--------------------+-------------+
|rockthejvm|Hello Spark, I am...|2024-01-11 11:16:...| 0|
+----------+--------------------+--------------------+-------------+
Source SparkStreaming to Kafka
1. Create dataframe with 2 columns: key & value
1
val carsKafkaDF = carsDF.selectExpr("upper(Name) as key", "Name as value")
2. Create consumer in Kafka to consume data from topic rockthejvm
An Apache Kafka® Consumer is a client application that subscribes to (reads and processes) events.
A consumer group is a set of consumers which cooperate to consume data from some topics.
Kafka consumers typically subscribe to topics and consume messages in real-time as they are produced. Few options to consume historical data:
Use --property print.key=true to print both key and value
1
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic rockthejvm
If any new data are producer to topic rockthejvm, consumer will consume that data. For example, we can write some data from producer to consumer

Check the simple Kafka Producer Application in Scala: KafkaProducerApp.scala
Or in Python, you can create a simple KafkaProducer by below syntax:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from kafka import KafkaProducer
from typing import Any
import json
def produce_message(topic: str, message: Any, key: str = None):
def json_serializer(data):
return json.dumps(data).encode('utf-8')
producer = KafkaProducer(
bootstrap_servers = ['localhost:9092'], # server name,
key_serializer = json_serializer, # function callable
value_serializer = json_serializer, # function callable
acks = 'all'
)
producer.send(
topic=topic,
key=key if key else "undefined",
value=message
)
produce_message(topic="rockthejvm",
message=[1, 3, 4])
3. Then write stream to Kafka topic as producer
Write a column value:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def writeToKafka() = {
val carsDF = spark.readStream
.schema(carsSchema)
.format("json")
.load("src/main/resources/data/cars")
val carsKafkaDF = carsDF.selectExpr("upper(Name) as key", "Name as value")
carsKafkaDF.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("topic", "rockthejvm")
.option("checkpointLocation", "checkpoints") // without checkpoints the writing to Kafka will fail
.start()
.awaitTermination()
}
Notes:
- Without
checkpointsthe writing to Kafka will fail,checkpointsfolder will be created. - ->
checkpointsdir will mark that which data has been sent to Kafka. - -> Need to remove checkpoints folder if we want to re-run the application and re-ingest all the data.
- Consumer from console will print all the
cars.Name(valuecolumn).
Write json string:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def writeCarsToKafka() = {
val carsDF = spark.readStream
.schema(carsSchema)
.json("src/main/resources/data/cars")
val carsJsonKafka = carsDF.select(
upper(col("Name")).as("key"),
to_json(struct(col("Name"), col("Horsepower"), col("Origin"))).cast("String").as("value")
)
carsJsonKafka.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("topic", "rockthejvm")
.option("checkpointLocation", "checkpoints") // without checkpoints the writing to Kafka will fail, checkpoints folder will be created
.start()
.awaitTermination()
}
Note:
- Once processed, changes to a file within the current window will not cause the file to be reread. I suggest using
Delta tableto read the change data storage.1 2 3
spark.readStream.format("delta") .option("ignoreDeletes", "true") .load("/tmp/delta/user_events")
- Need to rerun the application to re-consume all the old data
- If we want to insert file to folder, we need to copy new file to folder. -> New file data will be processed. And checkpoints will save the metadata for that file.
JDBC Integration
- So the batch is a static data set or data frame. Import data set in batches to manage data types Limitations:
- You can’t read streams from JDBC
- You cant’ write to JDBC in a streaming fashion … but you can write batches.
- New technique:
foreachBatch
See data after ingestion:
1
2
3
docker exec -it rockthejvm-sparkstreaming-postgres psql -U docker
\c rtjvm
Cassandra Integration (NoSQL database with no SPOF)
Before we get start: Run the container with init sql script
- Integrate a Cassandra NoSQL distributed store
- Learn how to use Cassandra Spark connector
- Learn Advanced technique: custom
ForeachWriter
See data after ingestion:
Before we get start: Create database instance in Cassandra
1
2
3
4
5
6
7
CREATE KEYSPACE public WITH REPLICATION = { 'class': 'SimpleStrategy', 'replication_factor': 1 };
CREATE TABLE public.cars(
"Name" text primary key,
"Horsepower" int);
SELECT * FROM public.cars;
ForeachWriter method
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
/**
* ForeachWriter: New advanced technique
* The abstract class for writing custom logic to process data generated by a query. */
class CarCassandraForeachWriter extends ForeachWriter[Cars] {
/*
* - On every batch, on every partition `partitionId`
* - On every "epoch" = chunk of data
* - call the open method; if false, skip this chunk
* - for each entry in this chunk, call the process method
* - call the close method either at the end of the chunk or with an error if it was thrown
* */
val keyspace = "public"
val table = "cars"
val connector = CassandraConnector(spark.sparkContext.getConf)
override def open(partitionId: Long, epochId: Long): Boolean = ???
override def process(value: Cars): Unit = ???
override def close(errorOrNull: Throwable): Unit = ???
}
3. Advanced - EventTimeWindow
Window functions on Structured Streaming:
- Aggregations on time-based groups
- Essential concepts:
- Window duration
- Window sliding intervals
Usage
1
2
3
4
5
6
7
8
val windowByDay = purchasesDF
.groupBy(window(col("time"), "1 day").as("time")) // struct column: has fields {start, end}
.agg(sum("quantity").as("totalQuantity"))
.select(
col("time").getField("start").as("start"), // or just "window.*
col("time").getField("end").as("end"),
col("totalQuantity")
)
Aggregation within 10 minute windows, updating every 5 minutes. (interval 5’ from start time)



Sliding window
In case of window-based aggregations, aggregate values are maintained for each window the event-time of a row falls into.
Window functions start at Jan 1 1970, 12 AM GMT (mid-night)
Slide window:
- windowDuration: 1 day > aggregate by 1 day from first record (eg: 2019-02-17 03:00:00 - 2019-02-18 03:00:00)
-
slideDuration: 1 hour => interval 1 hour from start time
- => Have 24 different records for a single batch. Return all the windows that contain the record time, and those records will be overlapped
Tumbling window
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
def betterSellingProductPerDay() = {
val purchasesDF = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 12345)
.load()
.select(from_json(col("value"), purchasesSchema).as("purchases"))
.select("purchases.*") // this will show up all column in the schema
val bestProductPurchasesDF = purchasesDF
.groupBy(
window(timeColumn = col("time"), windowDuration = "1 day").as("day"),
col("item"))
.agg(
sum(col("quantity")).as("totalQuantity"))
.orderBy(col("totalQuantity").desc_nulls_last)
.select(
col("day").getField("start").as("start"),
col("day").getField("end").as("end"),
col("item"),
col("totalQuantity")
)
bestProductPurchasesDF.writeStream
.format("console")
.outputMode("complete") // Append output mode not supported when there are streaming aggregations on streaming DataFrames/DataSets without watermark;
.trigger(
Trigger.ProcessingTime(2.seconds) // Continuous processing does not support Aggregate operations.
)
.start()
.awaitTermination()
}
Output
1
2
3
4
5
6
7
8
9
10
-------------------------------------------
+--------------------+-------+-------------+
| window| item|totalQuantity|
+--------------------+-------+-------------+
|{2019-02-28 07:00...|MacBook| 23|
|{2019-02-28 07:00...| Watch| 16|
|{2019-02-28 07:00...| iPad| 12|
|{2019-02-28 07:00...| TV| 10|
|{2019-02-28 07:00...| iPhone| 3|
+--------------------+-------+-------------+
E.g: With 4 records
1
2
3
4
{"id":"bba25784-487c-408b-9bba-d11ffec32010","time":"2019-02-28T17:02:41.675+02:00","item":"Watch","quantity":1}
{"id":"61d09e51-890e-425a-b7bf-c4bef5e23c2c","time":"2019-02-28T17:03:25.675+02:00","item":"Watch","quantity":9}
{"id":"2954aefd-71c2-47d9-b49a-d421b68b7b76","time":"2019-03-01T00:33:39.675+02:00","item":"iPhone","quantity":4}
{"id":"bf89d72a-e498-41b4-b7cc-f0ec3e0b1829","time":"2019-03-01T07:23:20.675+02:00","item":"iPad","quantity":6}
Return
1
2
3
4
5
6
+-------------------+-------------------+-------------+
| start| end|totalQuantity|
+-------------------+-------------------+-------------+
|2019-03-01 07:00:00|2019-03-02 07:00:00| 6|
|2019-02-28 07:00:00|2019-03-01 07:00:00| 14|
+-------------------+-------------------+-------------+
4. Advanced - Watermarking
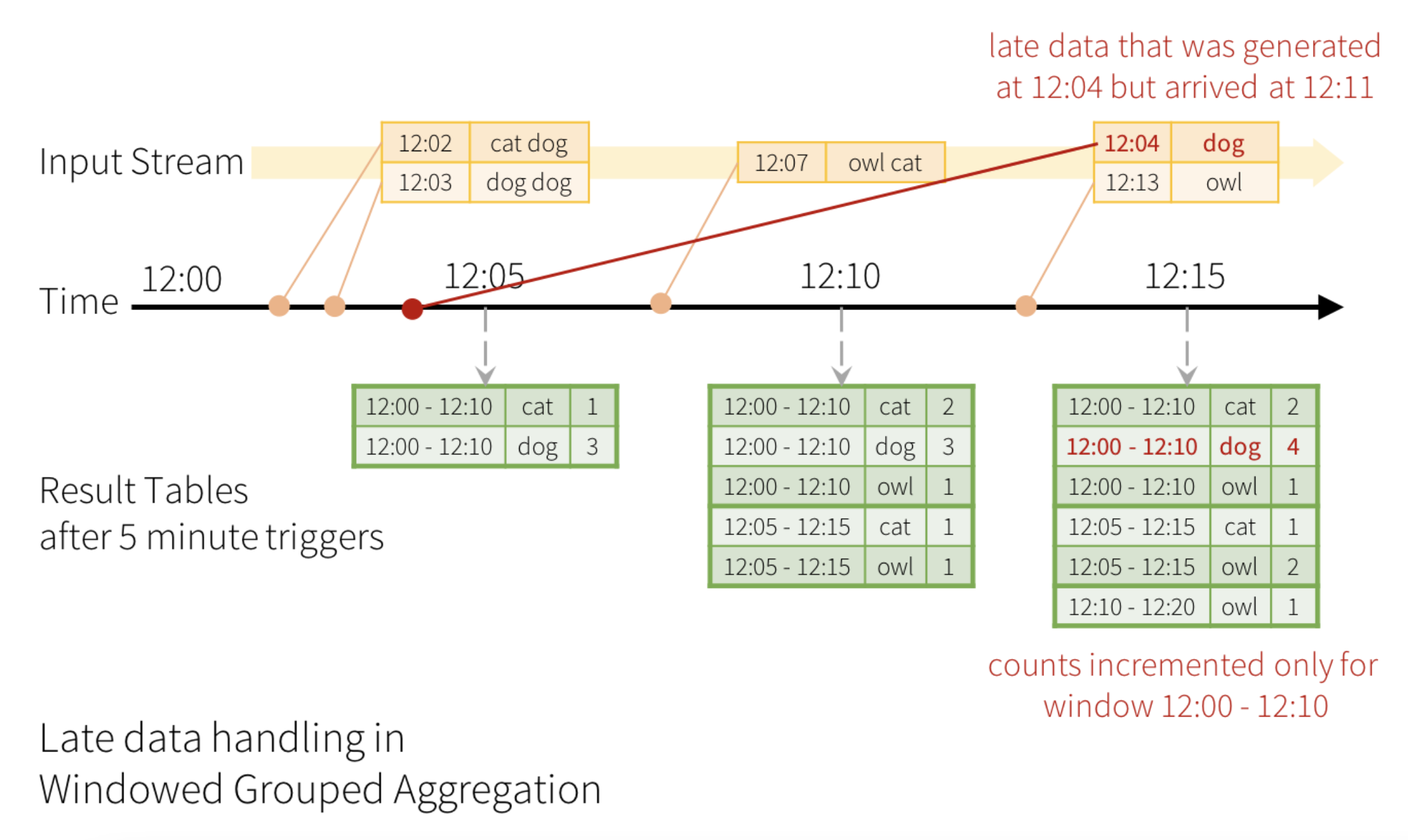
Watermarking is a feature in Spark Structured Streaming that is used to handle the data that arrives late. Spark Structured Streaming can maintain the state of the data that arrives, store it in memory, and update it accurately by aggregating it with the data that arrived late.
For example, say, a word generated at 12:04 (i.e. event time) could be received by the application at 12:11. The application should use the time 12:04 instead of 12:11 to update the older counts for the window 12:00 - 12:10.
How watermarking work
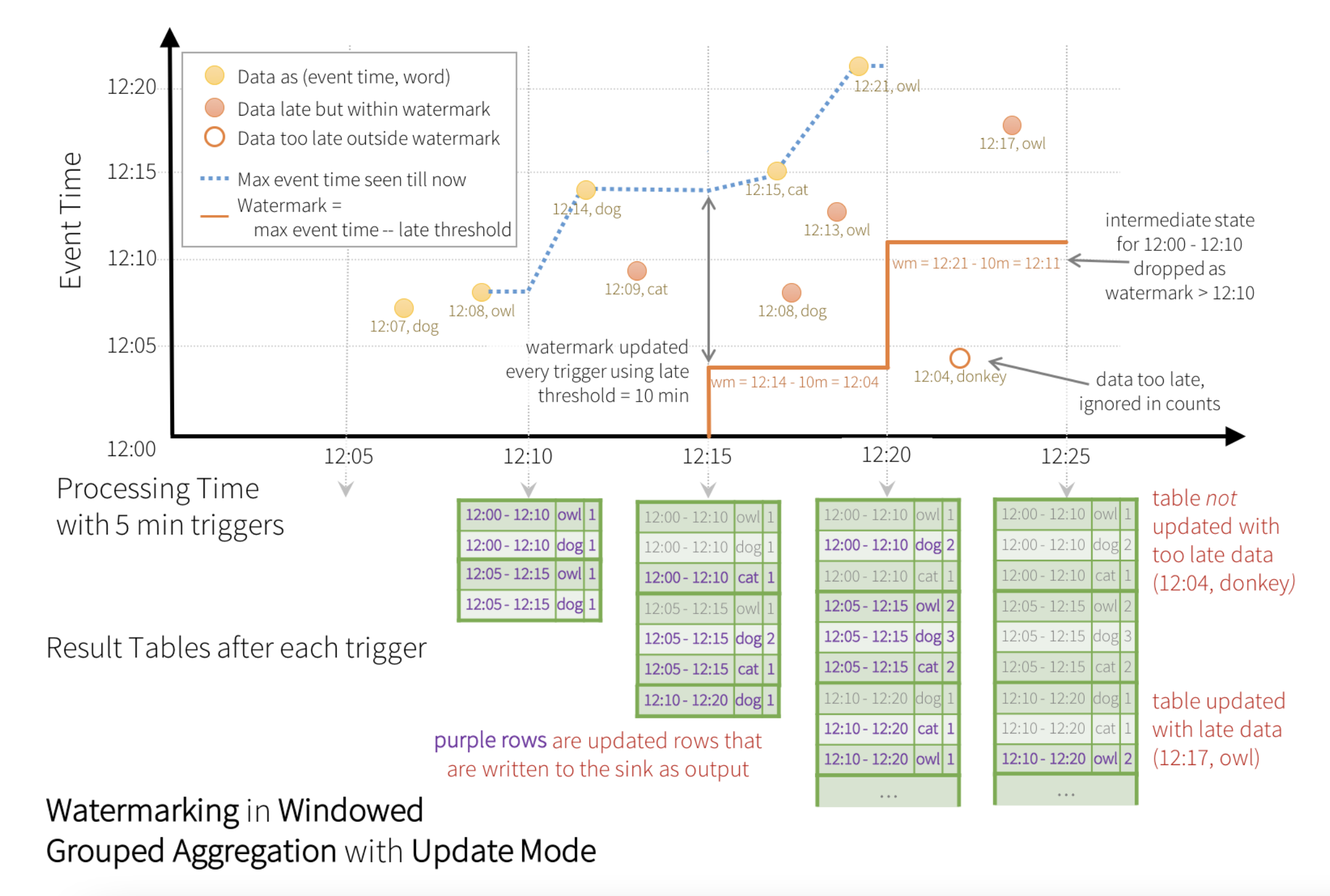 The engine waits for “10 mins” for late date to be counted, then drops intermediate state of a window < watermark, and appends the final counts to the Result Table/sink. For example, the final counts of window 12:00 - 12:10 is appended to the Result Table only after the watermark is updated to 12:11.
The engine waits for “10 mins” for late date to be counted, then drops intermediate state of a window < watermark, and appends the final counts to the Result Table/sink. For example, the final counts of window 12:00 - 12:10 is appended to the Result Table only after the watermark is updated to 12:11.
1
val enhancedDF = purchasesDF.withWatermark("created", "2 seconds") // eventTime, delayThreshold
With every batch, Spark will:
- update the max time ever recorded
- update watermarks as (max time - watermark duration)
Guarantees:
- In every batch, all records with time > watermark will be considered
- If using window function, a window will be updated util the watermark surpasses the window
No guarantees:
- Records whose time < watermark will necessarily be dropped
Aggregation & joins in append mode: Need watermarks
- A watermark allows Spark to drop old records from state management
Learn More
For more knowledge about my posts, reach me via [email protected]